Go1.17 新特性,凭什么提速 5~10%?
大家好,我是煎鱼。
在 Go1.17 发布后,我们惊喜的发现 Go 语言他又又又优化了,编译器改进后产生了约 5% 的性能提升,也没有什么破坏性修改,保证了向前兼容。
他做了些什么呢,好像没怎么看到有人提起。为此今天煎鱼带大家来解读两新提案:
- 《Proposal: Register-based Go calling convention》
- 《Proposal: Create an undefined internal calling convention》
本文会基于提案讲解和拆解,毕竟分享新知识肯定要从官方资料作为事实基准出发。
背景
在以往的 Go 版本中,Go 的调用约定简单且几乎跨平台通用,其原因在于选用了基于 Plan9 ABI 的堆栈调用约定,也就是函数的参数和返回值都是通过堆栈上来进行传递。
这里我们一共提到了 Plan9 和 ABI,这是两个很关键的理念:
- Plan9:Go 语言所使用的汇编器,Rob Pike 是贝尔实验室的猛人。
- ABI:Application Binary Interface(应用程序二进制接口),ABI 包含了应用程序在操作系统下运行时必须遵守的编程约定(例如:二进制接口)。
该方案的优缺点如下:
- 优点:实现简单,简化了实现成本。
- 缺点:性能方面付出了不少的代价。
按我理解,在 Go 语言初创时期,采取先简单实现,跑起来再说。也合理,性能倒不是一个 TOP1 需求。
Go1.17 优化
什么是调用惯例
在新版本的优化中,提到了调用惯例(calling convention)的概念,指的是调用方和被调用方对函数调用的共识约定。
这些共识包含:函数的参数、返回值、参数传递顺序、传递方式等。
双方都必须遵循这个约定时,程序的函数才能正常的运行起来。如果不遵循,那么该函数是没法运行起来的。
优化是什么
在 Go1.17 起,正式将把 Go 内部 ABI 规范(在 Go 函数之间使用)从基于堆栈的函数参数和结果传递的方式改为基于寄存器的函数参数和结果传递。
本次修改涉及到的项非常多,该优化是持续的,原本预计是 Go1.16 实现,不过拖到了 Go1.17。

目前实现了 amd64 和 arm64 架构的支持。还有不少的更多的支持会持续在 Go1.18 中完成,具体进度可见 issues #40724。
性能如何
在 Go1.17 Release Notes 中明确指出,用一组有代表性的 Go 包和程序的基准测试。
官方数据显示:
- Go 程序的运行性能提高了约 5%。
- Go 所编译出的二进制大小的减少约 2%。
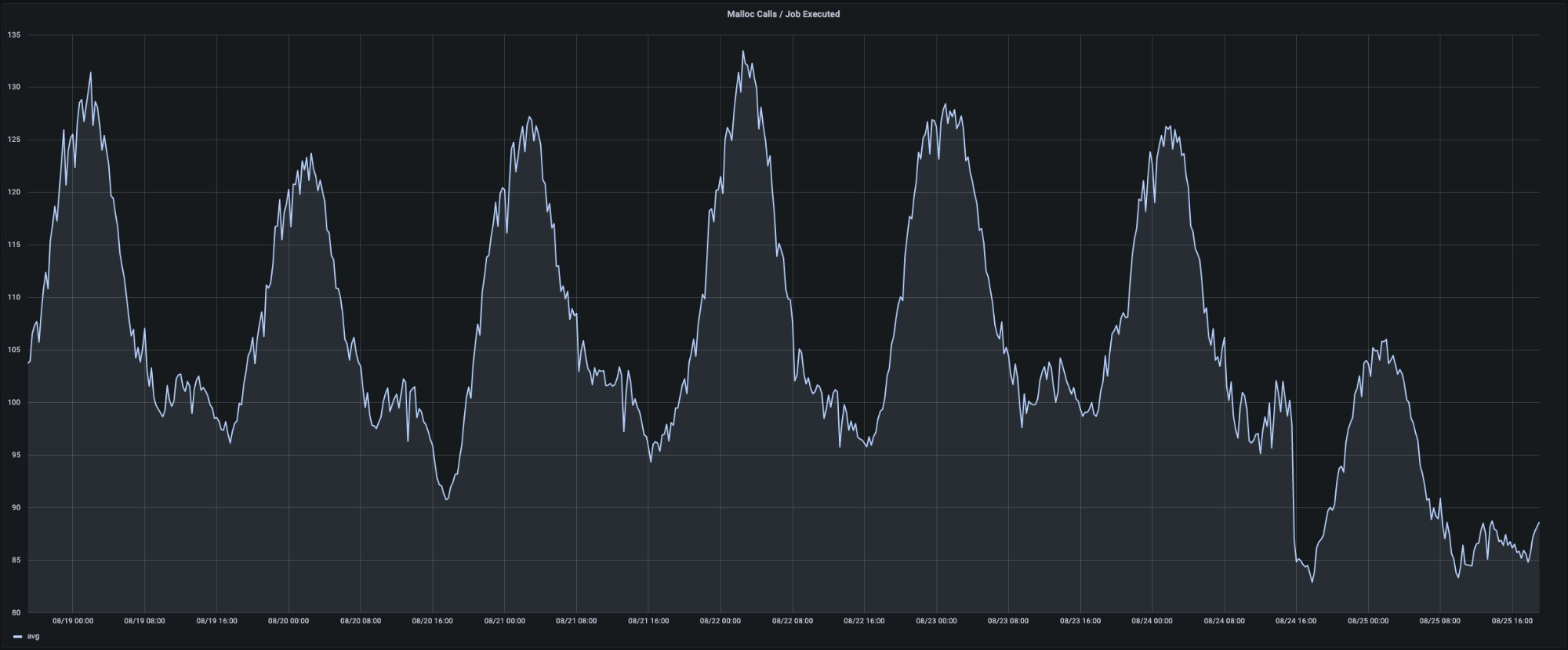
在民间数据来看,在 twitter 看到 @Achille 表示从 Go1.15.7 升级到 Go1.17 后显示。在一个大规模的数据处理系统上进行的 Go1.17 升级产生了惊人的效果,我们来看看他的真实数据。
CPU、Malloc 调用时间减少了约15%:

RSS 大小更接近于堆的大小:
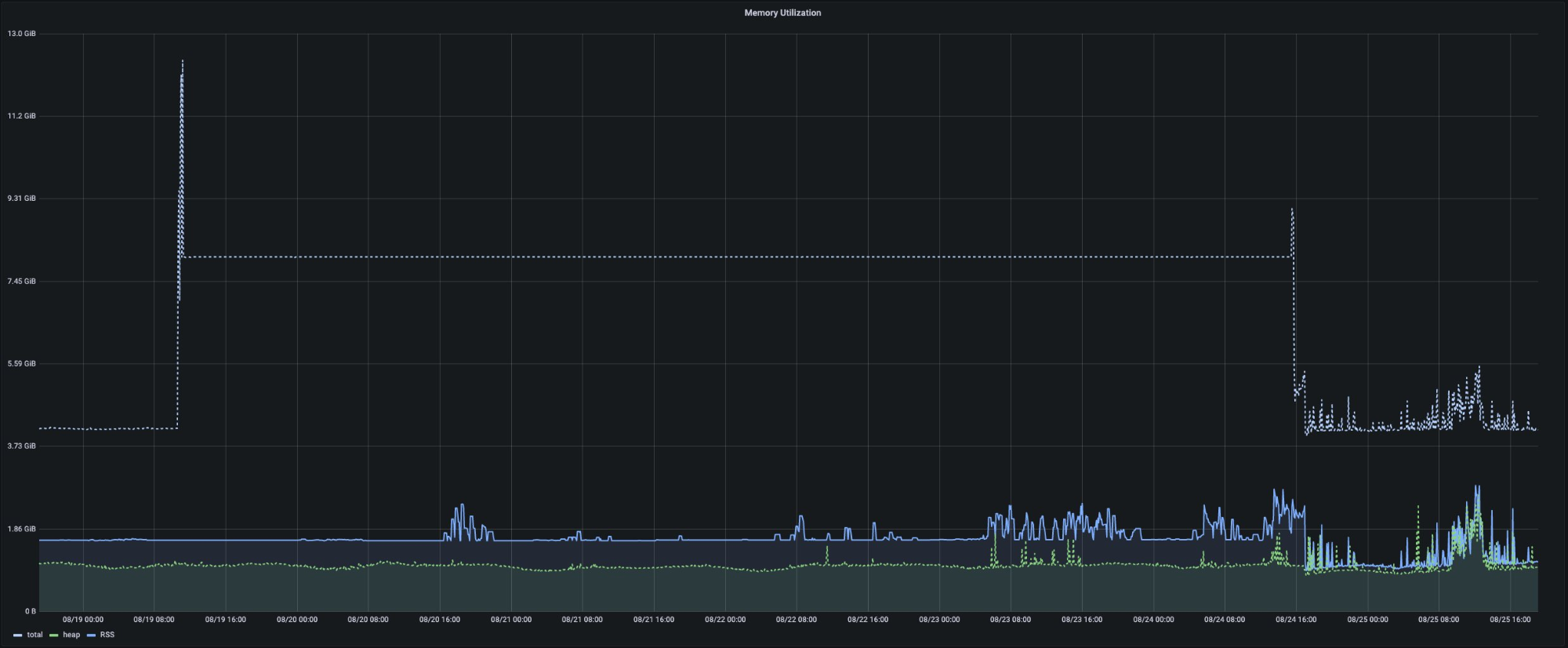
从原本的 1.6GB 降至 1GB。
结合官方和民间数据来看,优化效果是明确且有效的。有兴趣的小伙伴也可以自己测一测。
总结
在 Go1.17 这一个新版本中,只需要简单的升一升 Go 版本,我们就能得到一定的性能优化,这是非常不错的。
从以往的基于堆栈的函数参数和结果传递的方式改为 Go1.17~Go1.18 基于寄存器的函数参数和结果传递,Go 语言正在一步步走的更好!
你觉得呢?
