限流熔断是什么,怎么做,不做行不行?
“在分布式应用中,最常见的问题是什么呢?”
“一个分布式应用部署上去后,还要关注什么?”

“这服务的远程调用依赖似乎有点多…”
前言
在 《微服务的战争:级联故障和雪崩》中有提到,在一个分布式应用中,最常见,最有危险性之一的点就是级联故障所造成的雪崩,而其对应的解决方案为根据特定的规则/规律进行流量控制和熔断降级,避免请求发生堆积,保护自身应用,也防止服务提供方进一步过载。
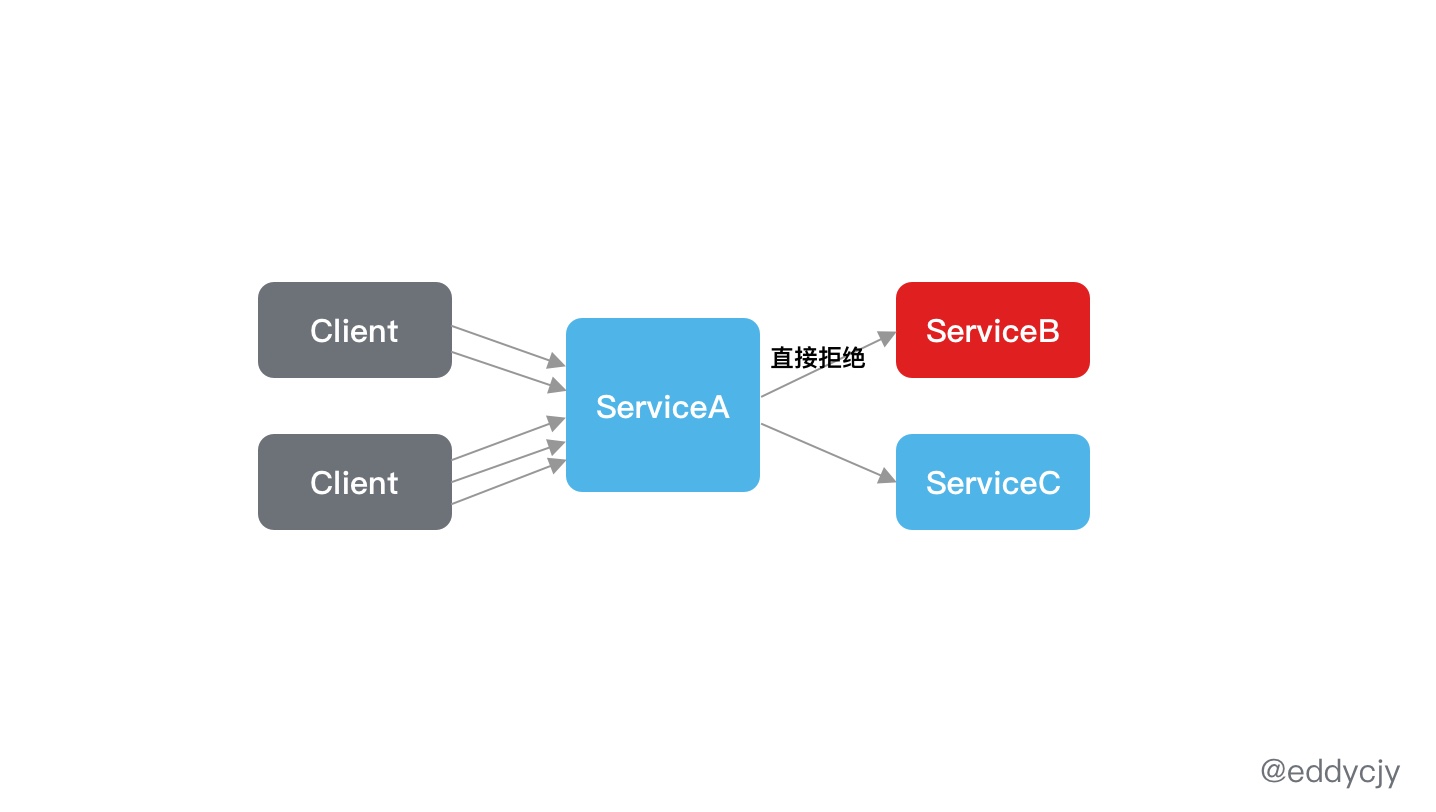
简单来讲就是,要控制访问量的流量,要防各类调用的强/弱依赖,才能保护好应用程序的底线。
诉求,期望
-
诉求:作为一个业务,肯定是希望自家的应用程序,能够全年无休,最低限度也要有个 4 个 9,一出突发性大流量,在资源贫乏的窗口期,就马上能够自动恢复。
-
期望:万丈高楼平地起,我们需要对应用程序进行流量控制、熔断降级。确保在特定的规则下,系统能够进行容错,只处理自己力所能及的请求。若有更一步诉求,再自动扩缩容,提高系统资源上限。
解决方案
要如何解决这个问题呢,可以关注到问题的核心点是 “系统没有任何的保护的情况下”,因此核心就是让系统,让你的应用程序有流量控制的保护。一般含以下几个方面:
-
来自端控制:在业务/流量网关处内置流量控制、熔断降级的外部插件,起到端控制的效果。
-
来自集群/节点控制:在统一框架中内建流量控制、熔断降级的处理逻辑,起到集群/节点控制的效果。
-
来自 Mesh 控制:通过 ServiceMesh 来实现流量控制、熔断降级。侵入性小,能带来多种控制模式,但有利有弊。
以上的多种方式均可与内部的治理平台打通,且流量控制、熔断降级是不止面试应用程序的,就看资源埋点上如何设计、注入。常见有如下几种角度:
-
资源的调用关系:例如远程调用,像是面向 HTTP、SQL、Redis、RPC 等调用均,另外针对文件句柄控制也可以。
-
运行指标:例如 QPS、线程池、系统负载等。
流量控制
在资源不变的情况下,系统所能提供的处理能力是有限的。而系统所面对的请求所到来的时间和量级往往是随机且不可控的。因此就会存在可能出现突发性流量,而在系统没有任何的保护的情况下,系统就会在数分钟内无法提供正常服务,常见过程为先是出现调用延迟,接着持续出现饱和度上升,最终假死。
流量控制一般常见的有两种方式,分别是:基于 QPS、基于并发隔离。
基于 QPS
最常用的流量控制场景,就是基于 QPS 来做流控,在一定的时间窗口内按照特定的规则达到所设定的阈值则进行调控:
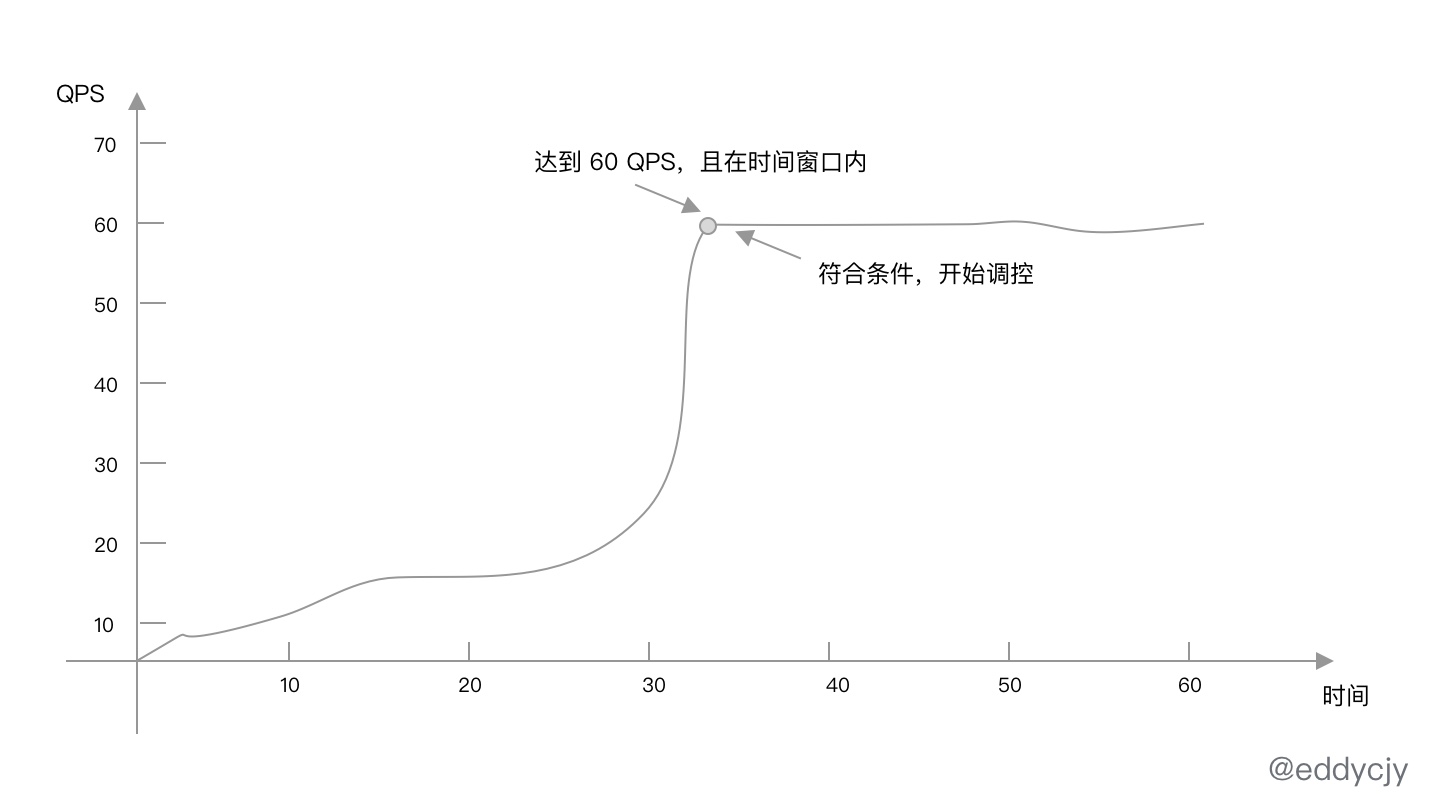
案例
在本文中借助 sentinel-golang 来实现案例所需的诉求,代码如下:
import (
...
sentinel "github.com/alibaba/sentinel-golang/api"
"github.com/alibaba/sentinel-golang/core/base"
"github.com/alibaba/sentinel-golang/core/flow"
"github.com/alibaba/sentinel-golang/util"
)
func main() {
_ = sentinel.InitDefault()
_, _ = flow.LoadRules([]*flow.Rule{
{
Resource: "控制吃煎鱼的速度",
Threshold: 60,
ControlBehavior: flow.Reject,
},
})
...
e, b := sentinel.Entry("控制吃煎鱼的速度", sentinel.WithTrafficType(base.Inbound))
if b != nil {
// Blocked
} else {
// Passed
e.Exit()
}
}
总的来讲,上述规则结果就是 1s 内允许通过 60 个请求,超出的请求的处理策略为直接拒绝(Reject)。
首先我们初始化了 Sentinel 并定义资源(Resource)为 “控制吃煎鱼的速度”。其 Threshold 配置为 3,也就是 QPS 的阈值为 3,统计窗口未设置默认值为 1s,ControlBehavior 控制的行为为直接拒绝。
而在满足阈值条件后,常见的处理策略还有匀速排队(Throttling),匀速排队方式会严格控制请求通过的间隔时间,也就是让请求以均匀的速度通过。
基于并发隔离
基于资源访问的并发协程数来控制对资源的访问数量,主要是控制对资源访问的最大协程数,避免因为资源的异常导致协程耗尽。
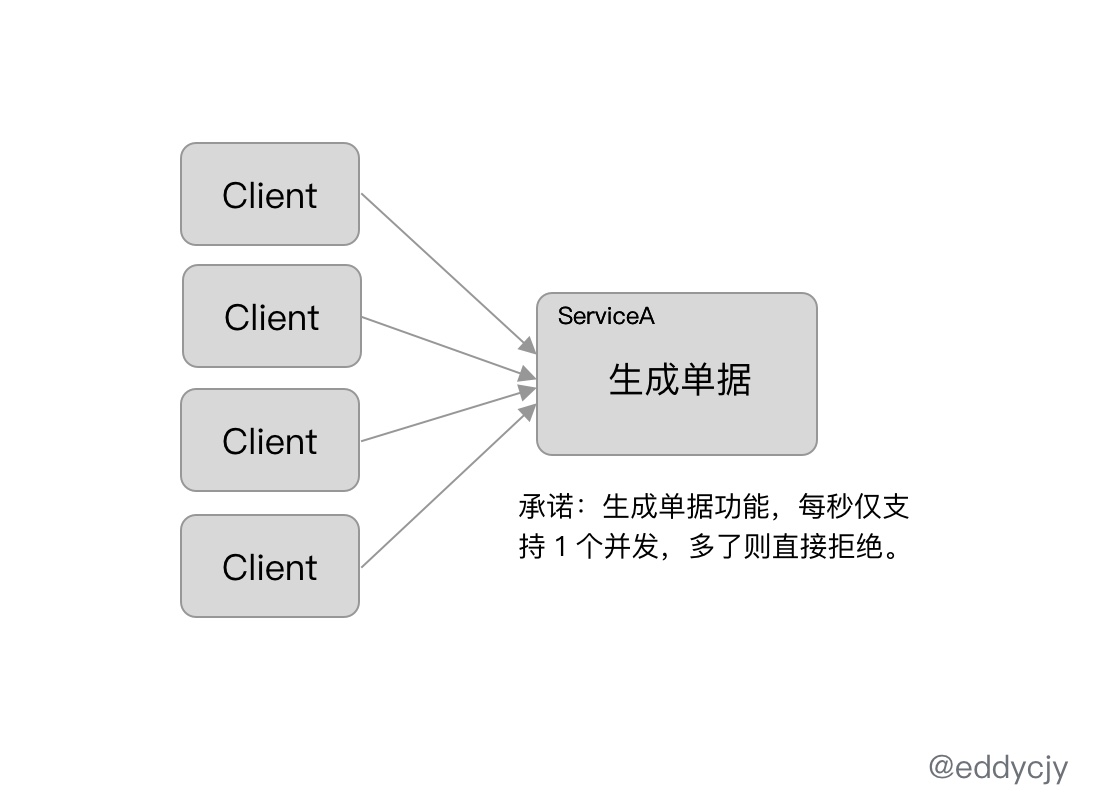
这类情况,Go 语言在设计上常常可以使用协程池来进行控制,但设计总是赶不上计划的,且不同场景情况可能不同,因此作为一个日常功能也是非常有存在的必要性。
熔断降级
在分布式应用中,随着不断地业务拆分,远程调用逐渐变得越来越多。且在微服务盛兴的情况下,一个小业务拆出七八个服务的也常有。
此时就会出现一个经典的问题,那就是客户端的一个普通调用,很有可能就要经过好几个服务,而一个服务又有可能远程调用外部 HTTP、SQL、Redis、RPC 等,调用链会特别的长。
若其中一个调用流程出现了问题,且没有进行调控,就会出现级联故障,最终导致系统雪崩:
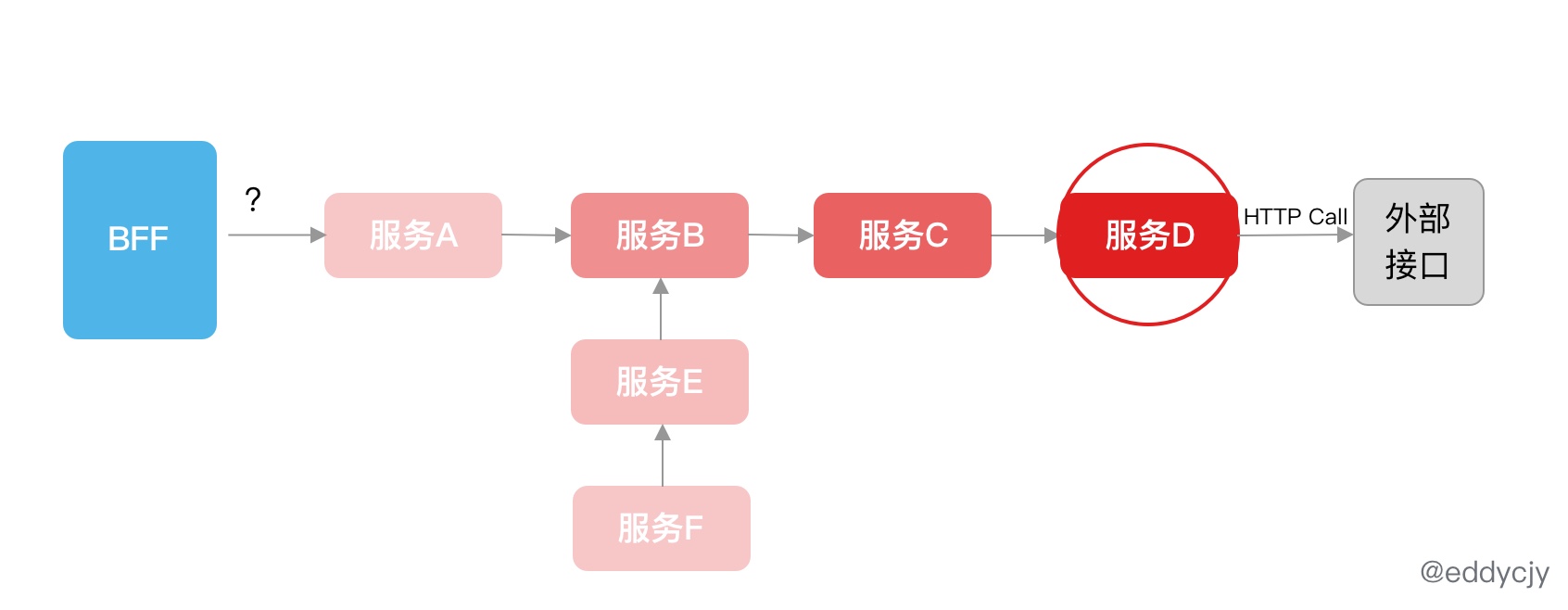
服务 D 所依赖的外部接口出现了故障,而他并没有做任何的控制,因此扩散到了所有调用到他的服务,自然也就包含服务 B,因此最终出现系统雪崩。
这种最经典的是出现在默认 Go http client 调用没有设置 Timeout,从而只要出现一次故障,就足矣让记住这类 “坑”,毕竟崩的 ”慢“,错误日志还多。(via: 《微服务的战争:级联故障和雪崩》)
目的和措施
为了解决上述问题所带来的灾难,在分布式应用中常需要对服务依赖进行熔断降级。在存在问题时,暂时切断内部调用,避免局部不稳定因素导致整个分布式系统的雪崩。
而熔断降级作为保护服务自身的手段,通常是在客户端进行规则配置和熔断识别:

常见的有三种熔断降级措施:慢调用比例策略、错误比例策略、错误计数策略。
慢调用比例
在所设定的时间窗口内,慢调用的比例大于所设置的阈值,则对接下来访问的请求进行自动熔断。
错误比例
在所设定的时间窗口内,调用的访问错误比例大于所设置的阈值,则对接下来访问的请求进行自动熔断。
错误计数
在所设定的时间窗口内,调用的访问错误次数大于所设置的阈值,则对接下来访问的请求进行自动熔断。
实践案例
知道流量控制、熔断降级的基本概念和功能后,在现实环境中应该如何结合项目进行使用呢。最常见的场景是可针对业务服务的 HTTP 路由进行流量控制,以 HTTP 路由作为资源埋点,这样子就可以实现接口级的调控了。
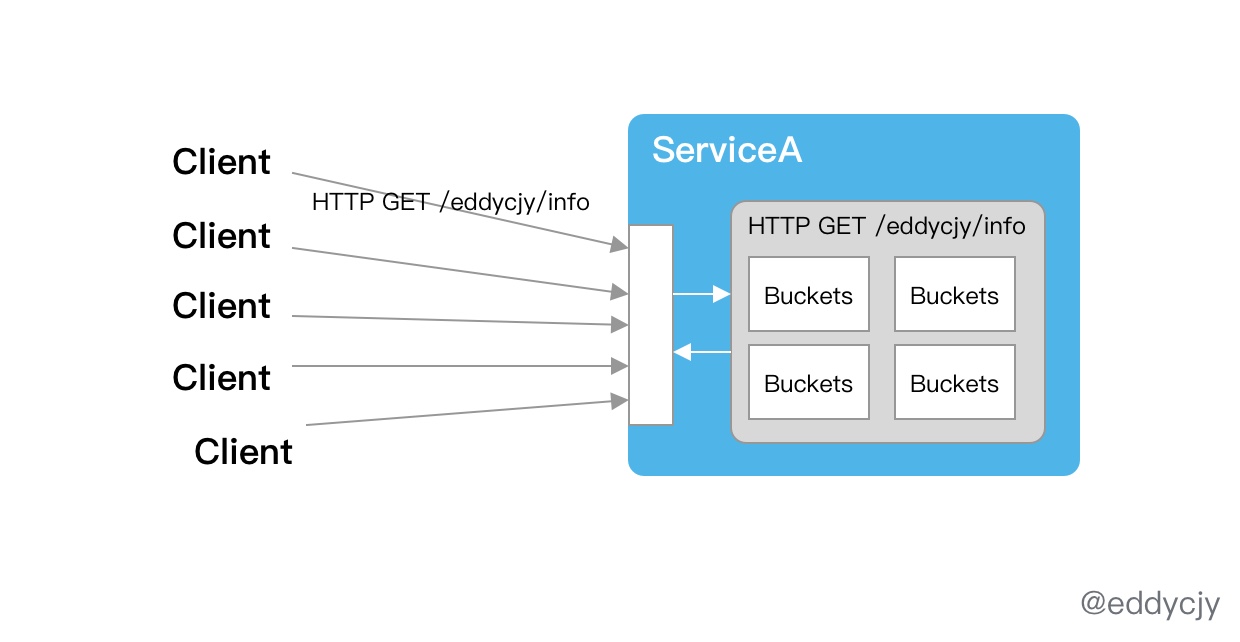
还可以增强其功能特性,针对参数也进行多重匹配。常会有这种限流诉求:针对 HTTP GET /eddycjy/info 且 language 为 go 的情况下进行限流。另外还可以针对 HTTP 调用封装统一方法,进行默认的熔断注入,实现多重保障。
而结合系统负载、服务 QPS 等,可以对限流熔断的规则数据源进行实时调控,再结合 Watch 机制,就能够比较平滑的实现自适应限流熔断的接入。
总结
在分布式应用中,限流熔断是非常重要的一环,越早开始做越有益处。但需要注意的是,不同公司的业务模型多多少少有些不一样,所针对的匹配维度多少有些不同,因此需要提前进行业务调研。
且在做业务的限流熔断时,注意把度量指标的打点做上,这样子后续就能够结合 Prometheus+Grafana+Alertmanager 做一系列的趋势图,熔断告警,自动扩缩容等相关工作了,会是一个很好的助力。
