《漫谈 MQ》设计 MQ 的 3 个难点
大家好,我是煎鱼。
前段时间我们分享了漫谈 MQ 的第一期《要消息队列(MQ)有什么用?》,感觉打开了一个新的世界。
但很快就有小伙伴意识到了不妙,既然 MQ 承接了多个系统,那岂不是该有的问题,他都有,又或是更甚。如下:

今天我们就进一步讲讲,设计 MQ 时很有可能会遇到的几个大难点,在业内又配套用了什么解决方案去处理。
几个难点
从结论上来看,设计 MQ 这一个存在。会至少引发三大难点。堪称互联网经典的,也是面试官们最爱问的:
- 高可用:代表系统的可用性程度,高可用性通常通过提高系统的容错能力来实现,从而减少系统宕机时间。
- 高并发:代表通过设计保证系统能够同时并行处理很多请求,在同一个时间点,有很多用户同时访问同一系统、API、URL。
- 高可靠:代表能够满足预计条件的一个系统或组件(例如:备份、故障处理、数据存储以及访问),比较经典的是 4 个9 等标准。
高可用
像前面评论区留言的兄弟截图表述的一样。
虽然请求不直接找系统 A、B、C、D 了。但是请求都实打实的通过异步的方式打到了 MQ 上,就可以不断往 MQ 塞,变成了多个系统都在请求 MQ,可以认为压力比单系统同步调用大了不止一倍。
同时 MQ 还要去做消费关系的维护,存储既有和新增的大量消息。是一个既要也要还要的典型场景。
这样一来,新的一轮问题就出现了。就是要保证 MQ 的高可用,否则他轻轻松松就会被压到宕机,或是负载过高,出现一些匪夷所思的延迟。
如何保证 MQ 的高可用,是一个大问题。
高并发
在高并发上的诉求上,其实是和高可用的场景是一样的。既然各业务系统都是异步的了,自然他也就不会像同步阻塞一样 “等” 你。
像是我有一个朋友,他们喜欢批量清洗多租户的数据。业务程序也不怎么节制,几十、几百、上千万数据,利用 Go 语言写的,抄起 for-loop+go func 就是一把梭。刷刷刷一下子就就给打进 MQ 里。
再多来几个业务系统这么干,这 MQ 并发就比较高了,单单维护就是头疼。很有可能事故背着背着,年底就 3.25 了。因为 MQ,在业务中的依赖非常重,是标准的核心基础设施。
如何保证 MQ 能够承受高并发,是一个大问题。
高可靠
对 MQ 来讲,高可靠性的诉求,又分为好几个角度去理解。如下:
- 消息要靠谱:“我” 发的消息要能够可靠的到达 MQ,MQ 要能够正确的让消费者能够接收到推送或拉取。
- 存储要靠谱:“我” 发的消息,还在 MQ 上时要存储好,不能发到 MQ 上就因为大量数据,丢了。又或是查询很慢。
- 处理要靠谱:发了消息,可能会出现异常。发了消息,可能网络抖动,没有接收到。
上述我们列了三点 “要靠谱” 的内容。实质上,对于 MQ 来讲,其每一块领域都要保证其可靠性,否则查起问题来,真的是会非常崩溃。
甚至更往上,还会对 “高性能” 会有要求,不过这一块我们就不进一步展开了。
解决方案
核心流程
在清楚了设计 MQ 会遇到的三大难点后。我们需要先了解一下现代 MQ 的基础应用架构会是怎么样的。
MQ 包含如下三类角色:
- 生产者(Producer):负责生产消息。
- 消费者(Consumer):负责消费消息。
- 服务端(Broker):负责存储和处理消息,是 MQ 的核心部分。由队列(Queue)延伸而来,因为功能已经不仅仅局限于队列属性了。
其核心流程如下:
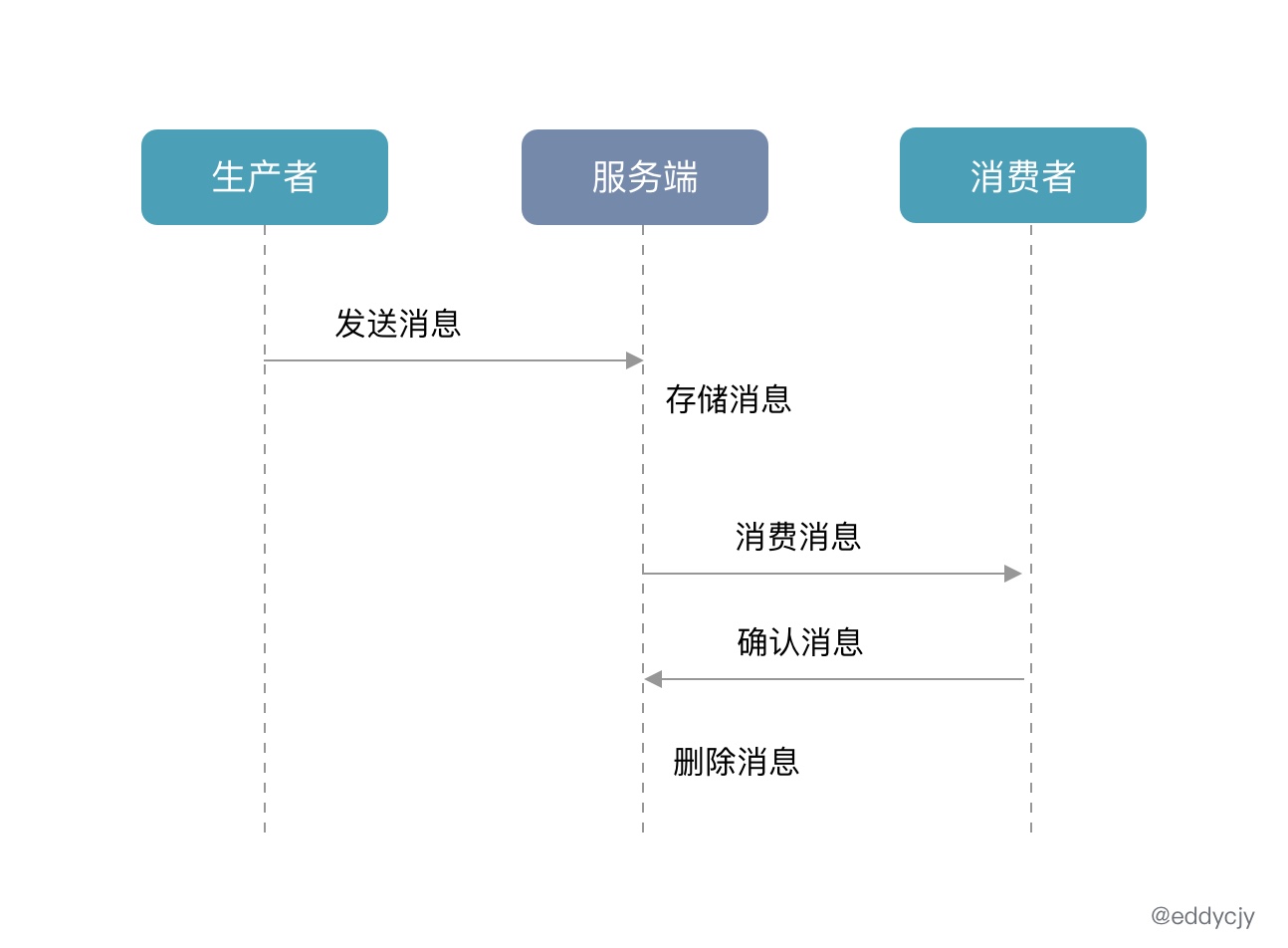
- 生产者(Producer)发送消息到达服务端(Broker),服务端进行消息存储,核心逻辑处理等。
- 再根据先前注册消费的关系(例如:订阅),进行消息的推送或被拉取。也就是消费消息了。
- 在完成消费消息后再返回确认(ACK)给服务端。若出现一定时间内未收到 ACK,则会触发服务端的重试机制。
- 服务端确定消息处理完毕,删除消息和进行记录。
对三高下手
设计高可用
在高可用上,主要要针对服务端(Broker)来做。目前常见的是保证服务端可以进行水平扩展,能够做跨集群的部署。
因此相应上得配套做服务的注册和发现机制,负载均衡(确保服务端压力均衡)。以此来构成 MQ 高可用的基本维持。
设计高并发
在高并发上,服务端必然包含队列(Queue),会起到缓冲的作用。但仍然可能会出现单点流量过大。
因此通常会结合像是 RocketMQ 的 Topic,Kafka 的 Partition 等做队列划分,起到分而治之的作用。
设计高可靠
在高可靠上,主要是针对消息发送、存储消息、处理消息这三块进行展开。
消息发送上,会结合 SDK 和服务端两者,发送和消费消息的确认(ACK)机制、重试机制等来实现消息的可靠性。
存储消息上,常见分为:分布式缓存、分布式文件系统、数据库方案等。目前主流的话,会采取落盘的方式,也就是将消息主体追加写入到日志文件,再配合索引文件来做快速的消息查找。
和 MySQL 数据库的存储模式是有一定的神似之处。
总结
在今天这篇文章中,我们面向设计 MQ 中常见的 3 大难点(其实还有更多,以后再介绍…)进行了逐一介绍和说明。同时也针对业内常见的解决方案进行了剖析。
在我们了解了这些细节后,在真正应用 MQ 时,就不会感到那么的无奈。因为常常你所遇到的,消息丢失,又或是消息重试导致裂变所导致宕机。
往往都来自于你所忽略的这些设计细节之中。即使对到用户端上只是几个简单的配置,你也应当理解这些知识 :)
