Prometheus 快速入门
一般我们说 Prometheus,有两种理解,我们平时需要注意识别的,其含义有两种,一是指的 Prometheus 自身,是一个时序数据库;另外一种是指 Prometheus 生态圈,指的是是整体的监控报警的生态圈和解决方案(Prometheus+Grafana+Alertmanager)。
Prometheus 在 2016年加入了 CNCF(Cloud Native Computing Foundation),是继 Kubernetes 之后的第二个托管项目,目前已经毕业,其主要的特点如下:
- 多维度的数据模型:由指标名称和键/值对标签标识的时间序列数据来组成多维的数据模型。
- 灵活的查询语言:在 Prometheus 中使用强大的查询语言 PromSQL 来进行查询。
- 不依赖分布式存储,Prometheus 单个节点也可以直接工作,支持本地存储(TSDB)和远程存储的模式。
- 服务端采集数据:Prometheus 基于 HTTP pull 方式去对不同的端采集时间序列数据。
- 客户端主动推送:支持通过 PushGateway 组件主动推送时间序列数据。
Prometheus 生态组件
Prometheus 生态由多个组件共同组成,其中许多组件是可根据实际情况选择的,并且绝大部分由 Go 语言编写,在部署和构建上比较方便,如下:
- Prometheus Server:Prometheus 服务端,用于收集指标和存储时间序列数据,并提供一系列的查询和设置接口。
- Client Libraries:客户端库,用于帮助需要监控采集的服务暴露 metrics handler 给 Prometheus server。例如像 例子 中直接调用 promhttp 暴露了一个 metrics 接口。
- Push Gateway:推送网关,Prometheus 服务端仅支持 HTTP pull 的采集方式,而有一些指存在的时间短,Prometheus 来 pull 前就结束了。又或是该类指标,就是要客户端自行上报的,这时候就可以采用 Push Gateway 的方式,客户端将指标 push 到 Push Gateway,再由 Prometheus Server 从 Pushgateway 上 pull。
- Exporters:用于暴露已有的第三方服务(HAProxy,StatsD,Graphite)的 metrics 给 Prometheus Server。
- Alertmanager:用于处理告警,从 Prometheus server 端接收到 alerts 后,会进行去重,分组,然后路由到对应的Receiver,发出报警。
- Support Tools:各种支持工具。
Prometheus 整体流程图
Prometheus 的整体架构和生态组件组成,如下图所示:

Prometheus Server 通过从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化。
Prometheus 采集的数据存到哪里
Prometheus 所有采集的指标数据在默认的情况下,都保存在本地所内置的时间序列数据库(TSDB)当中,如果需要另外调整,再将 Prometheus 的存储指向改为远程存储即可。
Prometheus 采用在默认情况下使用本地存储,能够一定的便利性,例如:开箱即用、运维方便(不用管)等等。但是也有不少缺点,像是海量数据无法持久化等等问题,因此强烈建议在上到企业级的海量应用时,一定对其进行研讨,适当考虑远程存储。
时序数据库是什么
Prometheus 是时序数据库(Time Series Database),又简称 TSDB。目前在行业中比较出名,流行度较高的时序数据库如下:
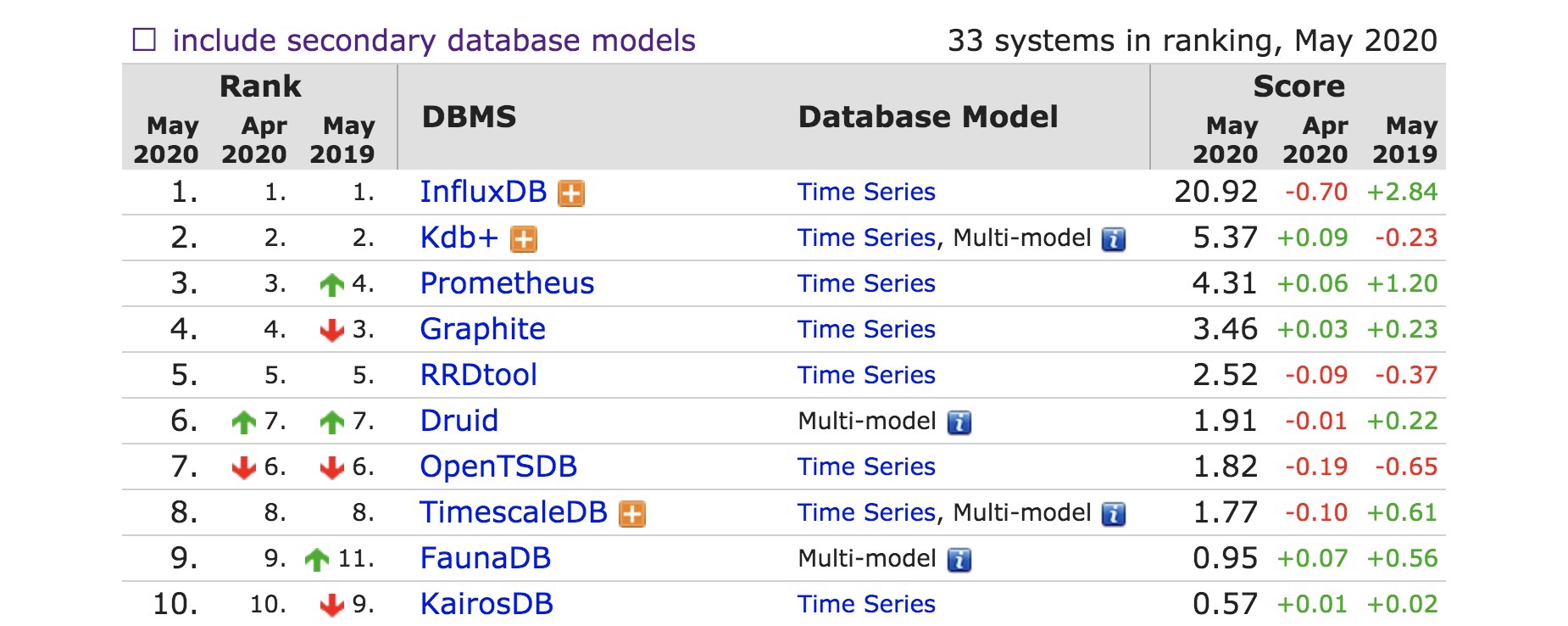
时序数据库简单来讲,就是将数据按照时间顺序排列,它具有唯一性和可排序性,因此在 Prometheus 的 Metrics 中即使只添加了一个新标签,也会造成破坏,也就是它不再是原本的那个时序数据了。
注:时序数据库是一个比较大的话题,后续会单独开一篇文章讲解,此处仅概要。
Prometheus 远程存储的方案
- AppOptics: write
- Azure Data Explorer: read and write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Graphite: write
- InfluxDB: read and write
- IRONdb: read and write
- Kafka: write
- M3DB: read and write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- QuasarDB: read and write
- SignalFx: write
- Splunk: read and write
- TiKV: read and write
- Thanos: write
- VictoriaMetrics: write
- Wavefront: write
数据持久化的意义
- 数据存储与服务提供应当隔离。
- 事故、问题的度量指标回溯。
- 数据挖掘的考虑。
- 提供给外部的自定义平台进行数据查询等等
- …
安装 Prometheus
Prometheus 是由 Go 语言编写的,因此安装非常的方便,只需要在 DOWNLOAD 中下载对应的 tar.gz 文件。进行如下解压:
$ tar xvfz prometheus-*.tar.gz
就可以看到下述目录:
prometheus
├── LICENSE
├── NOTICE
├── console_libraries
├── consoles
├── data
├── prometheus
├── prometheus.yml
├── prometheus.yml.default
├── promtool
├── rules
└── tsdb
启动 Prometheus:
$ ./prometheus
...
level=info ts=2020-05-16T07:33:34.138Z caller=main.go:661 msg="Starting TSDB ..."
level=info ts=2020-05-16T07:33:34.139Z caller=web.go:508 component=web msg="Start listening for connections" address=0.0.0.0:9090
默认监听 9090 端口:
至此我们就完成了 Prometheus 的基本启动了。
小结
在本章节中,我们快速了解 Prometheus 的基本概念和整体的生态概要,在下一章节起我们将进一步的实操,知行合一。
参考资料
