应用编译,计算机中那些一定要掌握的知识细节
”Hello World“ 程序几乎是每个程序员入门和开发环境测试的基本标准。代码如下:
#inclue <stdio.h>
int main()
{
printf("Hello Wolrd\n");
return 0;
}
编译该程序,再运行,就基本完成了所有新手的第一个程序。表面看起来轻轻松松,毫无悬念。但是实际上单纯这几下操作,就已经包含了不少暗操作。本着追根溯源的目的,我们将进一步对其流程进行分析。
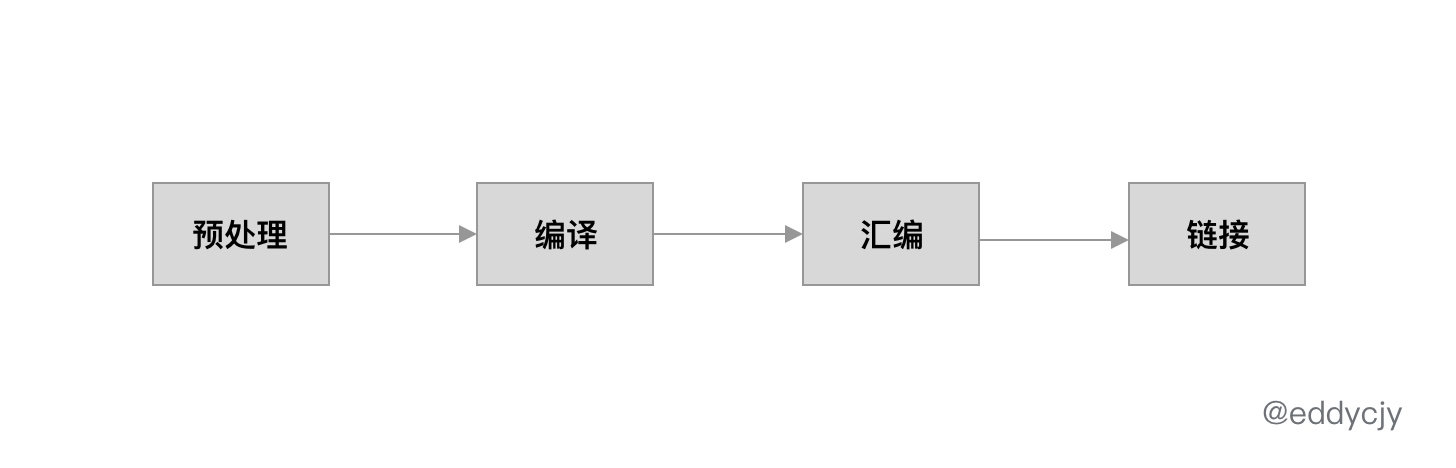
其内部主要包含 4 个步骤,分别是:预处理、编译、汇编以及链接。由于篇幅问题本文主要涉及前三部分,链接部分将会放到下一篇文章来讲解。
预编译
程序编译的第一步是 “预编译” 环境。主要作用是处理源代码文件中以 ”#“ 开始的预编译指令,例如:#include、#define 等。
常见的处理规则是:
-
将所有
#define删除,并且展开所有的宏定义。 -
处理所有条件预编译指令,比如
if、ifdef、elif、else、endif。 -
处理
#include预编译指令,将所包含的文件插入到该预编译指令的位置(可递归处理子级引入)。 -
删除所有的注释。
-
添加行号和文件名标识,以便于编译时编译器产生调试用的行号信息及用于编译时产生编译错误或警告时显示行号。
-
保留所有的
#pragma编译器指令,后续编译器将会使用。
在预编译后,文件中将不包含宏定义或引入。因为在预编译后将会全部展开,相应的代码段均已被插入文件中。像 Go 语言中的话,主要是 go generate 命令会涉及到相关的预编译处理。
编译
第二步正式进入到 “编译” 环境。主要作用是把预处理完的文件进行一系列词法分析、语法分析、语义分析及优化后生成相应的汇编代码文件。该部分通常是整个程序构建的核心部分,也是最复杂的部分之一。
执行编译操作的工具,一般称其为 “编译器”。编译器是将高级语言翻译成机器语言的一个工具。例如我们平时用 Go 语言写的程序,编译器就可以将其编译成机器可以执行的指令及数据。那么我们就不需要再去关心相关的底层细节,因为使用机器指令或汇编语言编写程序是一件十分费时及乏味的事情。
且高级语言能够使得程序员更关注程序逻辑的本身,不再需要过多的关注计算机本身的限制,具有更高的平台可移植性,能够在多种计算机架构下运行。
编译过程
编译过程一般分为 6 步:扫描、语法分析、语义分析、源代码优化、代码生成和目标代码优化。整个过程如下:

我们结合上图的源代码(Source Code)到最终目标代码(Final Target Code)的过程,以一段最简单的 Go 语言程序的代理例子来复现和讲述整个过程,如下:
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello World.")
}
词法分析
首先 Go 程序会被输入到扫描器中,可以理解为所有解析程序的第一步,都是读取源代码。而扫描器的任务很简单,就是利用有限状态机对源代码的字符序列进行分割,最终变成一系列的记号(Token)。
如下 Hello World 利用 go/scanner 进行处理:
1:1 package "package"
1:9 IDENT "main"
1:13 ; "\n"
3:1 import "import"
3:8 ( ""
4:2 STRING "\"fmt\""
4:7 ; "\n"
5:1 ) ""
5:2 ; "\n"
7:1 func "func"
7:6 IDENT "main"
7:10 ( ""
7:11 ) ""
7:13 { ""
8:2 IDENT "fmt"
8:5 . ""
8:6 IDENT "Println"
8:13 ( ""
8:14 STRING "\"Hello World.\""
8:28 ) ""
8:29 ; "\n"
9:1 } ""
9:2 ; "\n"
在经过扫描器的扫描后,可以看到输出了一大堆的 Token。如果没有前置知识的情况下,第一眼可能会非常懵逼。在此可以初步了解一下 Go 所主要包含的标识符和基本类型,如下:
// Special tokens
ILLEGAL Token = iota
EOF
COMMENT
// Identifiers and basic type literals
// (these tokens stand for classes of literals)
IDENT // main
INT // 12345
FLOAT // 123.45
IMAG // 123.45i
CHAR // 'a'
STRING // "abc"
literal_end
再根据所输出的 Token 稍加思考,做对比,就可得知其仅是单纯的利用扫描器翻译和输出。而实质上在识别记号时,扫描器也会完成其他工作,例如把标识符放到符号表,将数字、字符串常量存放到文字表等。
词法分析产生的记号一般可以分为如下几类:
-
关键字。
-
标识符。
-
字面量(包含数字、字符串等)。
-
特殊符合(如加号、等号)
语法分析/语义分析
语法分析器
语法分析器(Grammar Parser)将对扫描器所产生的记号进行语法分析,从而产生语法树(Syntax Tree),也称抽象语法树(Abstract Syntax Tree,AST)。
常见的分析方式是自顶向下或者自底向上,以及采取上下文无关语法(Context-free Grammer)作为分析手段。这块可参考一些计算机理论的资料,涉及的比较广。
但语法分析仅完成了对表达式的语法层面的分析,但并不清楚这个语句是否真正有意义,还需要一步语义分析。
语义分析器
语义分析器(Semantic Analyzer)将会对对语法分析器所生成的语法树上的表达式标识具体的类型。主要分为两类:
-
静态语义:在编译器就可以确定的语义。
-
动态语义:在运行期才可以确定的语义。
在经过语义分析阶段后,整个语法树的表达式都会被标识上类型,如果有些类型需要进行隐式转换,语义分析程序将会在语法书中插入相应的转换点,成为有更具体含义的语义。
实战演练
语法分析器生成的语法树,本质上就是以表达式(Expression)为节点的树。在 Go 语言中可通过 go/token、go/parser、go/ast 等相关方法生成语法树,代码如下:
func main() {
src := []byte("package main\n\nimport (\n\t\"fmt\"\n)\n\nfunc main() {\n\tfmt.Println(\"Hello World.\")\n}")
fset := token.NewFileSet() // positions are relative to fset
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
ast.Print(fset, f)
}
其经过语法分析器(自顶下向)分析后会所输出的结果如下:
0 *ast.File {
1 . Package: 1:1
2 . Name: *ast.Ident {
3 . . NamePos: 1:9
4 . . Name: "main"
5 . }
6 . Decls: []ast.Decl (len = 2) {
7 . . 0: *ast.GenDecl {
8 . . . TokPos: 3:1
9 . . . Tok: import
10 . . . Lparen: 3:8
11 . . . Specs: []ast.Spec (len = 1) {
12 . . . . 0: *ast.ImportSpec {
13 . . . . . Path: *ast.BasicLit {
14 . . . . . . ValuePos: 4:2
15 . . . . . . Kind: STRING
16 . . . . . . Value: "\"fmt\""
17 . . . . . }
18 . . . . . EndPos: -
19 . . . . }
20 . . . }
21 . . . Rparen: 5:1
22 . . }
23 . . ...
71 . }
72 . Scope: *ast.Scope {
73 . . Objects: map[string]*ast.Object (len = 1) {
74 . . . "main": *(obj @ 27)
75 . . }
76 . }
77 . Imports: []*ast.ImportSpec (len = 1) {
78 . . 0: *(obj @ 12)
79 . }
80 . Unresolved: []*ast.Ident (len = 1) {
81 . . 0: *(obj @ 46)
82 . }
83 }
-
Package:解析出 package 关键字的位置,1:1 指的是位置在第一行的第一个。
-
Name:解析出 package name 的名称,类型是
*ast.Ident,1:9 指的是位置在第一行的第九个。 -
Decls:节点的顶层声明,其对应 BadDecl(Bad Declaration)、GenDecl(Generic Declaration)、FuncDecl(Function Declaration)。
-
Scope:在此文件中的函数作用域,以及作用域对应的对象。
-
Imports:在此文件中所导入的模块。
-
Unresolved:在此文件中未解析的标识符。
-
Comments:在此文件中的所有注释内容。
可视化后的语法树如下:

在上文中,主要涉及语法分析和语义分析部分,其归属于编译器前端,最终结果是得到了语法树,也就是常说是抽象语法树(AST)。有兴趣可以亲自试试 yuroyoro/goast-viewer,会对语法树的理解更加的清晰。
中间语言生成
现代的编译器有这多个层次的优化,通常源代码级别会有一个优化过程。例如单纯的 1+2 的表达式就可以被优化。而在 Go 语言中,中间语言则会涉及静态单赋值(Static Single Assignment,SSA)的特性。
假定有一个很简单的 SayHelloWorld 方法,如下:
package helloworld
func SayHelloWorld(a int) int {
c := a + 2
return c
}
想看到源代码到中间语言,再到 SSA 的话,可通过 GOSSAFUNC 编译源代码并查看:
$ GOSSAFUNC=SayHelloWorld go build helloworld.go
# command-line-arguments
dumped SSA to ./ssa.html
打开 ssa.html,可看到这个文件源代码所对应的语法树,好几个版本的中间代码以及最终所生成的 SSA。
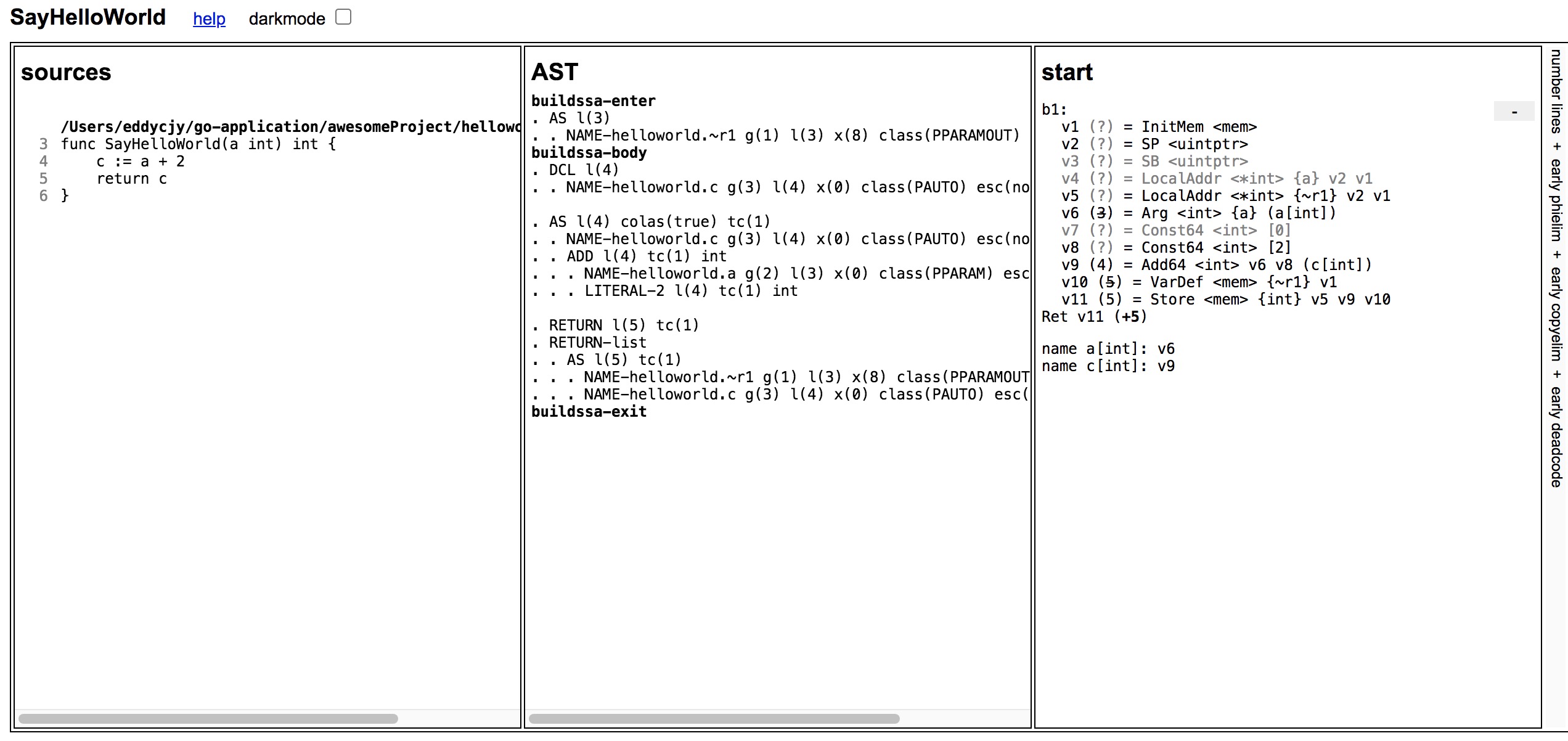
从左往右依次为:Sources(源代码)、AST(抽象语法树),其次最右边第一栏起就是第一轮中间语言(代码),后面还有十几轮。
目标代码生成与优化
在中间语言生成完毕后,还不能直接使用。因为机器真正能执行的是机器码。这时候就到了编译器后端的工作了。在源代码级优化器产生中间代码时,则标志着接下来的过程都属于编译器后端。
编译器后端主要包括如下两类,作用如下::
-
代码生成器(Code Generator):代码生成器将中间代码转换成目标机器代码。
-
目标代码优化器(Target Code Optimizer):针对代码生成器所转换出的目标机器代码进行优化。
在 Go 语言中,以上行为包含在前面所提到的十几轮 SSA 优化降级中,有兴趣可自行研究 SSA,最后在 genssa 中可看见最终的中间代码:
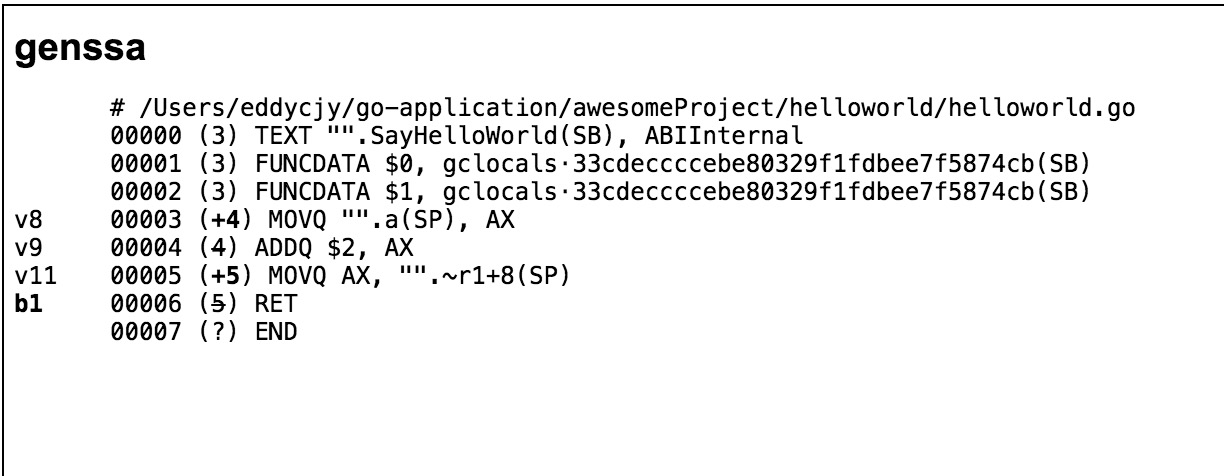
此时的代码已经降级的与最终的汇编代码比较接近,但还没经过正式的转换。
汇编
完成程序编译后,第三步将是 ”汇编“,汇编器会将汇编代码转变成机器可执行的指令,每一个汇编语句几乎都对应着一条机器指令。基本逻辑就是根据汇编指令和机器指令的对照表一一翻译。
在 Go 语言中,genssa 所生成的目标代码已经完成了优化降级,接下来会调用 src/cmd/internal/obj 包中的汇编器将 SSA 中间代码生成为机器码。我们可通过 go tool compile -S 的方式进行查看:
$ go tool compile -S helloworld.go
"".SayHelloWorld STEXT nosplit size=15 args=0x10 locals=0x0
0x0000 00000 (helloworld.go:3) TEXT "".SayHelloWorld(SB), NOSPLIT|ABIInternal, $0-16
0x0000 00000 (helloworld.go:3) FUNCDATA $0, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (helloworld.go:3) FUNCDATA $1, gclocals·33cdeccccebe80329f1fdbee7f5874cb(SB)
0x0000 00000 (helloworld.go:4) MOVQ "".a+8(SP), AX
0x0005 00005 (helloworld.go:4) ADDQ $2, AX
0x0009 00009 (helloworld.go:5) MOVQ AX, "".~r1+16(SP)
0x000e 00014 (helloworld.go:5) RET
0x0000 48 8b 44 24 08 48 83 c0 02 48 89 44 24 10 c3 H.D$.H...H.D$..
go.cuinfo.packagename. SDWARFINFO dupok size=0
0x0000 68 65 6c 6c 6f 77 6f 72 6c 64 helloworld
gclocals·33cdeccccebe80329f1fdbee7f5874cb SRODATA dupok size=8
0x0000 01 00 00 00 00 00 00 00 ........
至此就完成了一个高级语言再到计算机所能理解的机器码转换的完整流程了。
总结
在本文中,我们基本了解了一个应用程序是怎么从源代码编译到最终的机器码,其中每一步展开都是一块非常大的计算机基础知识。若有读者对其感兴趣,可根据文中的实操步骤进行深入的剖析和了解。
在下一篇文章中,将会进一步针对最后的一个步骤链接来进行分析和了解其最后一公里。
