为什么容器内存占用居高不下,频频 OOM
最近我在回顾思考(写 PPT),整理了现状,发现了这个问题存在多时,经过一番波折,最终确定了元凶和相对可行的解决方案,因此也在这里分享一下排查历程。
时间线:
-
在上 Kubernetes 的前半年,只是用 Kubernetes,开发没有权限,业务服务极少,忙着写新业务,风平浪静。
-
在上 Kubernetes 的后半年,业务服务较少,偶尔会阶段性被运维唤醒,问之 “为什么你们的服务内存占用这么高,赶紧查”。此时大家还在为新业务冲刺,猜测也许是业务代码问题,但没有调整代码去尝试解决。
-
在上 Kubernetes 的第二年,业务服务逐渐增多,普遍增加了容器限额 Limits,出现了好几个业务服务是内存小怪兽,因此如果不限制的话,服务过度占用会导致驱逐,因此反馈语也就变成了:“为什么你们的服务内存占用这么高,老被 OOM Kill,赶紧查”。据闻也有几个业务大佬有去排查(因为 OOM 反馈),似乎没得出最终解决方案。
不禁让我们思考,为什么个别 Go 业务服务,Memory 总是提示这么高,经常达到容器限额,以至于被动 OOM Kill,是不是有什么安全隐患?
现象
内存居高不下
发现个别业务服务内存占用挺高,触发告警,且通过 Grafana 发现在凌晨(没有什么流量)的情况下,内存占用量依然拉平,没有打算下降的样子,高峰更是不得了,像是个内存炸弹:
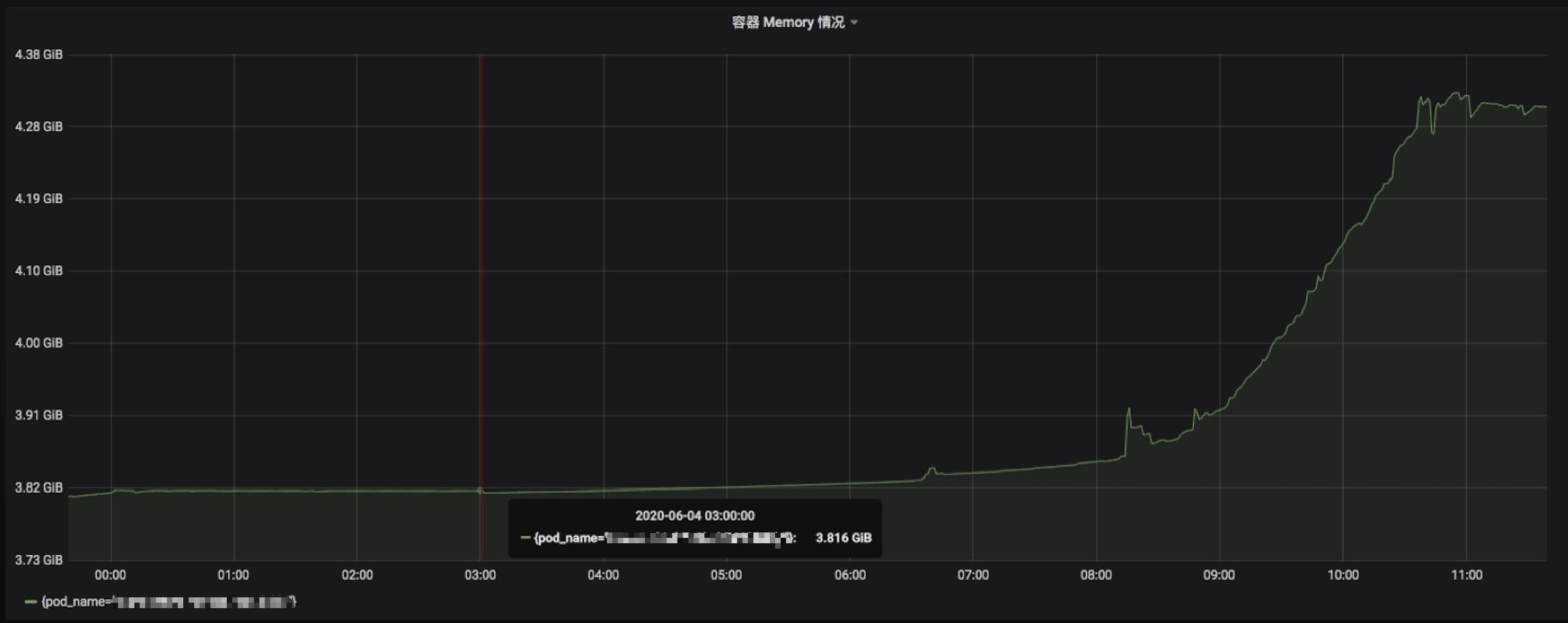
并且我所观测的这个服务,早年还只是 100MB。现在随着业务迭代和上升,目前已经稳步 4GB,容器限额 Limits 纷纷给它开道,但我想总不能是无休止的增加资源吧,这是一个大问题。
进入重启怪圈
有的业务服务,业务量小,自然也就没有调整容器限额,因此得不到内存资源,又超过额度,就会进入疯狂的重启怪圈:

重启将近 300 次,非常不正常了,更不用提所接受到的告警通知。
排查
猜想一:频繁申请重复对象
出现问题的个别业务服务都有几个特点,那就是基本为图片处理类的功能,例如:图片解压缩、批量生成二维码、PDF 生成等,因此就怀疑是否在量大时频繁申请重复对象,而 Go 本身又没有及时释放内存,因此导致持续占用。
sync.Pool
基本上想解决 “频繁申请重复对象”,我们大多会采用多级内存池的方式,也可以用最常见的 sync.Pool,这里可参考全成所借述的《Go 夜读》上关于 sync.Pool 的分享,关于这类情况的场景:
当多个 goroutine 都需要创建同⼀个对象的时候,如果 goroutine 数过多,导致对象的创建数⽬剧增,进⽽导致 GC 压⼒增大。形成 “并发⼤-占⽤内存⼤-GC 缓慢-处理并发能⼒降低-并发更⼤”这样的恶性循环。
验证场景
在描述中关注到几个关键字,分别是并发大,Goroutine 数过多,GC 压力增大,GC 缓慢。也就是需要满足上述几个硬性条件,才可以认为是符合猜想的。
通过拉取 PProf goroutine,可得知 Goroutine 数并不高:
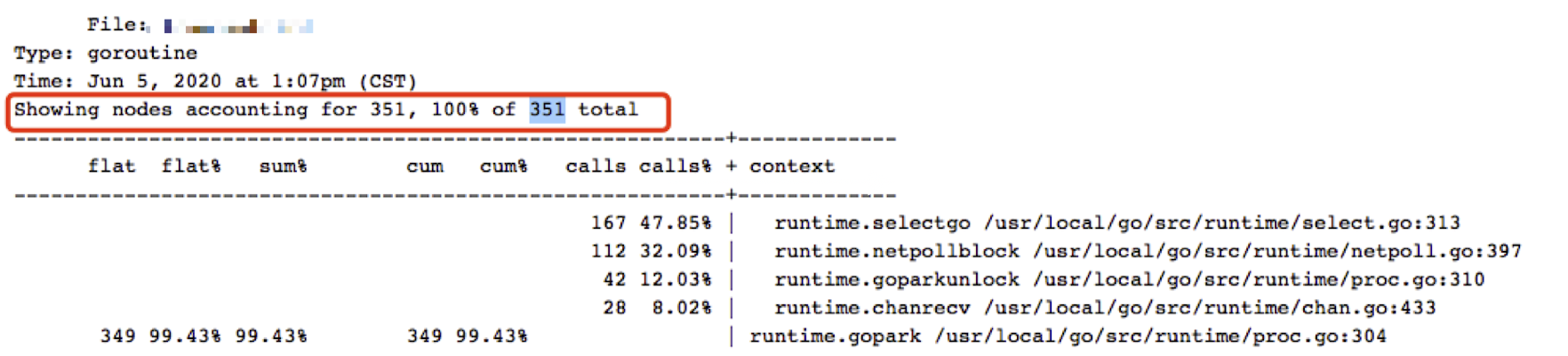
另外在凌晨长达 6 小时,没有什么流量的情况下,也不符合并发大,Goroutine 数过多的情况,若要更进一步确认,可通过 Grafana 落实其量的高低。
从结论上来讲,我认为与其没有特别直接的关系,但猜想其所对应的业务功能到导致的间接关系应当存在。
猜想二:不知名内存泄露
内存居高不下,其中一个反应就是猜测是否存在泄露,而我们的容器中目前只跑着一个 Go 进程,因此首要看看该 Go 应用是否有问题。这时候可以借助 PProf heap(可以使用 base -diff):

显然其提示的内存使用不高,那会不会是 PProf 出现了 BUG 呢。接下通过命令也可确定 Go 进程的 RSS 并不高,但 VSZ 却相对 “高” 的惊人,我在 19 年针对此写过一篇《Go 应用内存占用太多,让排查?(VSZ篇)》 ,这次 VSZ 过高也给我留下了一个念想。
从结论上来讲,也不像 Go 进程内存泄露的问题,因此也将其排除。
猜想三:madvise 策略变更
-
在 Go1.12 以前,Go Runtime 在 Linux 上使用的是
MADV_DONTNEED策略,可以让 RSS 下降的比较快,就是效率差点。 -
在 Go1.12 及以后,Go Runtime 专门针对其进行了优化,使用了更为高效的
MADV_FREE策略。但这样子所带来的副作用就是 RSS 不会立刻下降,要等到系统有内存压力了才会释放占用,RSS 才会下降。
查看容器的 Linux 内核版本:
$ uname -a
Linux xxx-xxx-99bd5776f-k9t8z 3.10.0-693.2.2.el7.x86_64
但 MADV_FREE 的策略改变,需要 Linux 内核在 4.5 及以上(详细可见 go/issues/23687),显然不符合,因此也将其从猜测中排除。
猜想四:监控/判别条件有问题
会不会是 Grafana 的图表错了,Kubernetes OOM Kill 的判别标准也错了呢,显然不大可能,毕竟我们拥抱云,阿里云 Kubernetes 也运行了好几年。

但在这次怀疑中,我了解到 OOM 的判断标准是 container_memory_working_set_bytes 指标,因此有了下一步猜想。
猜想五:容器环境的机制
既然不是业务代码影响,也不是 Go Runtime 的直接影响,那是否与环境本身有关呢,我们可以得知容器 OOM 的判别标准是 container_memory_working_set_bytes(当前工作集)。
而 container_memory_working_set_bytes 是由 cadvisor 提供的,对应下述指标:

从结论上来讲,Memory 换算过来是 4GB+,石锤。接下来的问题就是 Memory 是怎么计算出来的呢,显然和 RSS 不对标。
原因
从 cadvisor/issues/638 可得知 container_memory_working_set_bytes 指标的组成实际上是 RSS + Cache。而 Cache 高的情况,常见于进程有大量文件 IO,占用 Cache 可能就会比较高,猜测也与 Go 版本、Linux 内核版本的 Cache 释放、回收方式有较大关系。

而各业务模块常见功能,如:
- 批量图片解压缩。
- 批量二维码生成。
- 批量上传渲染后图片。
- 批量 PDF 生成。
- …
只要是涉及有大量文件 IO 的服务,基本上是这个问题的老常客了,写这类服务基本写一个中一个,因为这是一个混合问题,像其它单纯操作为主的业务服务就很 “正常”,不会出现内存居高不下。
解决方案
在本场景中 cadvisor 所提供的判别标准 container_memory_working_set_bytes 是不可变更的,也就是无法把判别标准改为 RSS,因此我们只能考虑掌握主动权。
开发角度
使用类 sync.Pool 做多级内存池管理,防止申请到 “不合适”的内存空间,常见的例子: ioutil.ReadAll:
func (b *Buffer) ReadFrom(r io.Reader) (n int64, err error) {
…
for {
if free := cap(b.buf) - len(b.buf); free < MinRead {
newBuf := b.buf
if b.off+free < MinRead {
newBuf = makeSlice(2*cap(b.buf) + MinRead) // 扩充双倍空间
copy(newBuf, b.buf[b.off:])
}
}
}
}
核心是做好做多级内存池管理,因为使用多级内存池,就会预先定义多个 Pool,比如大小 100,200,300的 Pool 池,当你要 150 的时候,分配200,就可以避免部分的内存碎片和内存碎块。
但从另外一个角度来看这存在着一定的难度,因为你怎么知道什么时候在哪个集群上会突然出现这类型的服务,何况开发人员的预期情况参差不齐,写多级内存池写出 BUG 也是有可能的。
让业务服务无限重启,也是不现实的,被动重启,没有控制,且告警,存在风险。
运维角度
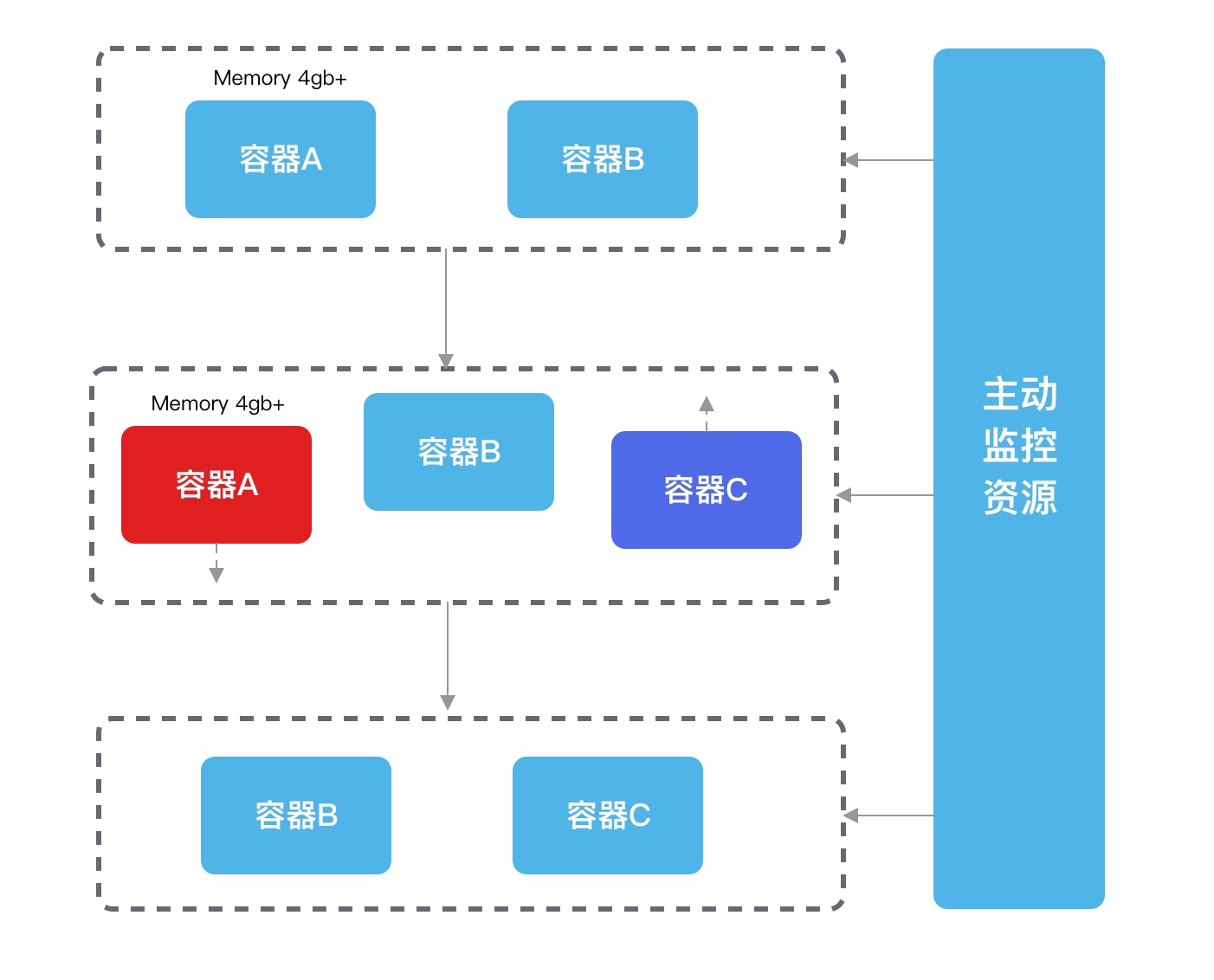
为了掌握主动权,我们可以在部署环境可以配合脚本做 “手动” HPA,当容器内存指标超过约定限制后,起一个新的容器替换,再将原先的容器给释放掉,就可以在预期内替换且业务稳定了。
总结
根据上述排查和分析结果,原因如下:
- 应用程序行为:文件处理型服务,导致 Cache 占用高。
- Linux 内核版本:版本比较低(BUG?),不同 Cache 回收机制。
- 内存分配机制:在达到 cgroup limits 前会尝试释放,但可能内存碎片化,也可能是一次性索要太多,无法分配到足够的连续内存,最终导致 cgroup oom。

从根本上来讲,应用程序需要去优化其内存使用和分配策略,又或是将其抽离为独立的特殊服务去处理。并不能以目前这样简单未经多级内存池控制的方式去使用,否则会导致内存使用量越来越大。
而从服务提供的角度来讲,我们并不知道这类服务会在什么地方出现又何时会成长起来,因此我们需要主动去控制容器的 OOM,让其实现优雅退出,保证业务稳定和可控。
因此如果可以,升级 Linux 内核版本走 cgroup v2 极有可能可以解决问题。
回顾
虽然这问题时间跨度比较长,整体来讲都是阶段性排查,本质上可以说是对 Kubernetes 的不熟悉有关。但综合来讲这个问题涉及范围比较大,因为内存居高不下的可能性有很多种,要一个个排查,开发权限有限,费时费力。
基本排查思路就是:
- 怀疑业务代码(PProf)。
- 怀疑其它代码(PProf)。
- 怀疑 Go Runtime 。
- 怀疑工具。
- 怀疑环境。
非常感谢在这大段时间内被我咨询的各位大佬们,感觉就是隔了一层纱,捅穿了就很快就定位到了,大家如果有其它解决方案也欢迎随时沟通。
