我周末参加了个架构师大会!
大家好,我是煎鱼。
前两天 GIAC 全球互联网架构大会在深圳举办了,总算是有个长年在深圳举办的大会了,愉快参加了大部分的场次,面基了不少社区网友。
分享一些我听了觉得有意义的记录给大家。希望能和大家一起学习进步。本文分别涉及如下几个议题:
- 《hits for microservices desgin》
- 《在企业中的个人成长》
- 《大规模任务调度在 AfterShip 的高可用实践》
- 《快手前端实时性能监控和稳定性度量》
- 《快手中间件 mesh 化实践》
hits for microservices desgin
一开始先介绍了为什么叫 ”hits“。叫 ”hits“ 的主要原因,是业务架构没有技术架构那么明确,没有明确的对与错,是个人的工作经验和总结。
微服务解决什么问题
业内常常说到,微服务,微服务。总归期望微服务解决什么问题。
演讲的作者做了如下的调研:
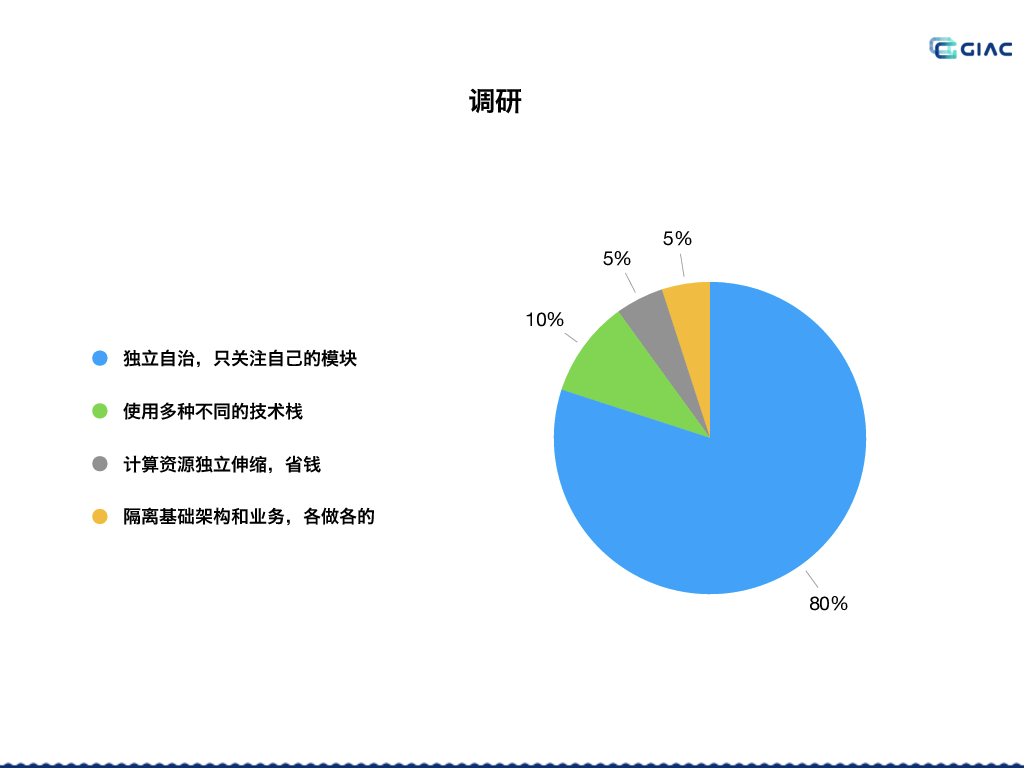
从调研结果来看,占比最大的就是 ”独立自治,只关注自己的模块“。这和绝大部分既有业务的公司做微服务的初衷一致。
许多就是被单体的巨石应用折腾的不行,纷纷希望通过拆分微服务来实现业务模块的独立自治。
微服务的现状
主要是播放了动图,配合口述。现在大多数服务拆分后的现状,很多就是改哪影响哪完全不清楚,和水管漏水似的:
(自行脑补一拧水管,堵哪,别的地方就漏)
衡量微服务拆分的标准
理想中的微服务拆分,希望要有灵活的组装能力。但拆分后遇到的新问题,实际的情况,拆分后与期望的不一样,拆着拆着就变成了一大坨,但只是说隔开了,与现在企业中微服务运行的现状很贴合。
拆分后如有如下几个痛点:

举了几个案例。分别是:
- 订单的例子。
- 报价的系统。
- 数仓的例子。
订单
举的是订单的例子,订单团队非常忙,因为信息都存在订单里,系统其他有任何业务上的变更诉求,都要找订单的团队。
为此,在拆分上需要优化成订单业务只保存订单 ID:

各系统存订单ID,各团队自治,实现业务解耦,订单团队就不用因其他业务变更天天加班了。
报价
举的是报价的系统,要是报价团队,针对各个子业务项都要自己实现一般,会非常的辛苦,经常要加班。
我们只需要在报价系统提供接口标准,各系统自己实现,再对接:
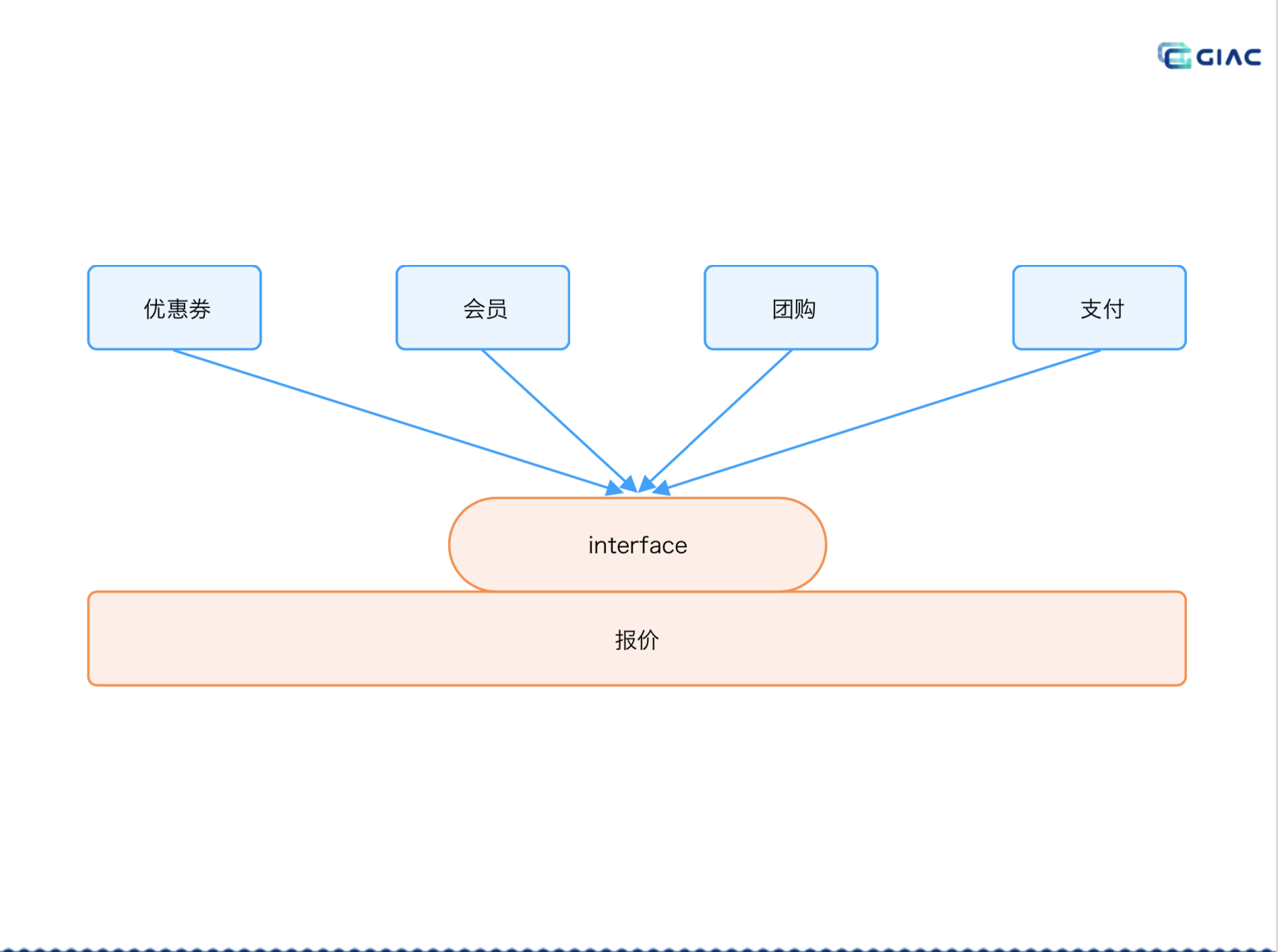
报价团队就不需要每次都重新开会,再对接。报价系统自己只做业务流程的编排,瞬间变轻松了。
数仓
举的是数仓的例子,业务改一个字段,数仓系统要改一个月,否则就会出现问题,因此要求业务有任何 schema 改变都必须要通知数仓团队:

很现实的是,基本通知不过来,所以很多公司把他作为绩效,定期考核,出问题定期批评。
建议的是:通过 RPC 的方式提供维护,把数据维护交给业务团队自己维护,数仓团队应该只做具体的跨团队的数据互联。
好的标准的定义
分层,都可以独立变更,可以自己搞自己,只需要保证这一层提供的能力是稳定的就好(全部改一遍的另当别论),不需要了解上下游,只需要维护好 interface。
具体几点:
- 不同模块间完全没影响
- 只共享不可变数据
- 共享可变数据,但接口不变。
- 大部分情况变化的是实现,变化的不是接口,接口的变更次数很少。
参照乐高,关注接口的稳定性,而不是拆的越细越好。
评价的标准是:看不同系统不同模块的互相影响程度,就知道各系统怎么样了。
小结
- 不要在一开始就使用有意义的名词,例如:交易中心,支付中心。大家会根据名字来设计的架构,建议最后再起名字。
- 复用不是目的,是手段。例如业务中台真的是复用吗,不是。只是互联互通。
- 好的架构,是要控制复杂度,在一定的规范下尽量自治。
- 先划分清楚业务模块,划分清楚了,再去设计你的技术架构。
提问时也有涉及到 ”分布式事务“,这简直就是微服务相关议题的必问话题。演讲者表示:倾向持续交付。尽可能不让他有分布式事务。
在企业中的个人成长
毛老师的演讲,据说全场综合评分最高,内容是分享了自己在企业成长的三个阶段:
- 阶段一:加入 Startup 公司。
- 阶段二:轮岗。
- 阶段三:重新出发。
分享比较有明确的时间线,我是直接按点来记录的,刚好十条,非常经典。
十条纲要
-
15 年,也不知道什么是 B 站,也找不到人。从以前认识的一些熟人,从别的公司挖回来。小公司,亲自带。自己熟悉业务,请教老员工文化。
-
团队到 40~50 就要考虑做人才梯队了。要保证每个月有 1v1 的简单聊一聊,或是每天现场聊聊。稳定性问题和管理有关系,有没有研发红线,例如发布变更,生产无小事。
-
改变一个人性格非常困难,只能告诉他,给一两次机会。不合适就放弃,心慈刀快,尽快解决掉。合适的人,给过两三次机会,自己早就转变过来了,两三次还不行,肯定是难以改变的了。
-
要做核心的事情,不要什么需要都做。不要用技术实现去挑战老板的战略考虑,要用业务。
-
不要害怕空降,引入新的人,有竞争压力,有进步,要做减法,聚焦最重要的事情。向他们学习,看他们的优势,择机成长。
-
要换位思考,站在平台方,成就业务。最好的团建是一起拿成果。从老板的角度考虑,绝对能折腾,绝对能将就,就像基础架构部门,有时候要业务优先。
-
影响力,技术辐射范围足够广,不同团队落地,自然而然就有了影响力。公司外的影响力,多分享,多参加 meetup。
-
哪里有需要就去哪里。
-
OKR 要足够的透明,足够的明确。下级要知道,要清楚,甚至是自下而上的 OKR。
-
团队的会模仿你,看别人的缺点,修正自己。自己在团队中要做榜样(举例:早点下班的问题)。
小结
在职业生涯发展上的小伙伴,建议可以看看毛老师的分享 PPT,看看大佬从 0 到千亿万身家的个人成长发展史。
就如总结所说的:”当你很忙碌的时候,你的管理工作一定出了问题“,值得思考。
大规模任务调度在 AfterShip 的高可用实践
初始的业务需求是有优先级调度的需求,用户的调度比物流包裹的优先级高。
任务调度的量比较大,要能运行千万级的优先级任务调度。
老版本
老版本是根据 15 分钟划分一个 Topic,可以理解为分区,一天 96 个。
采取的是轮询策略,还没执行的放进延迟队列。实现了 15 分钟粒度级别的任务级别(没法做到 1 分钟,5分钟的这类纬度)。
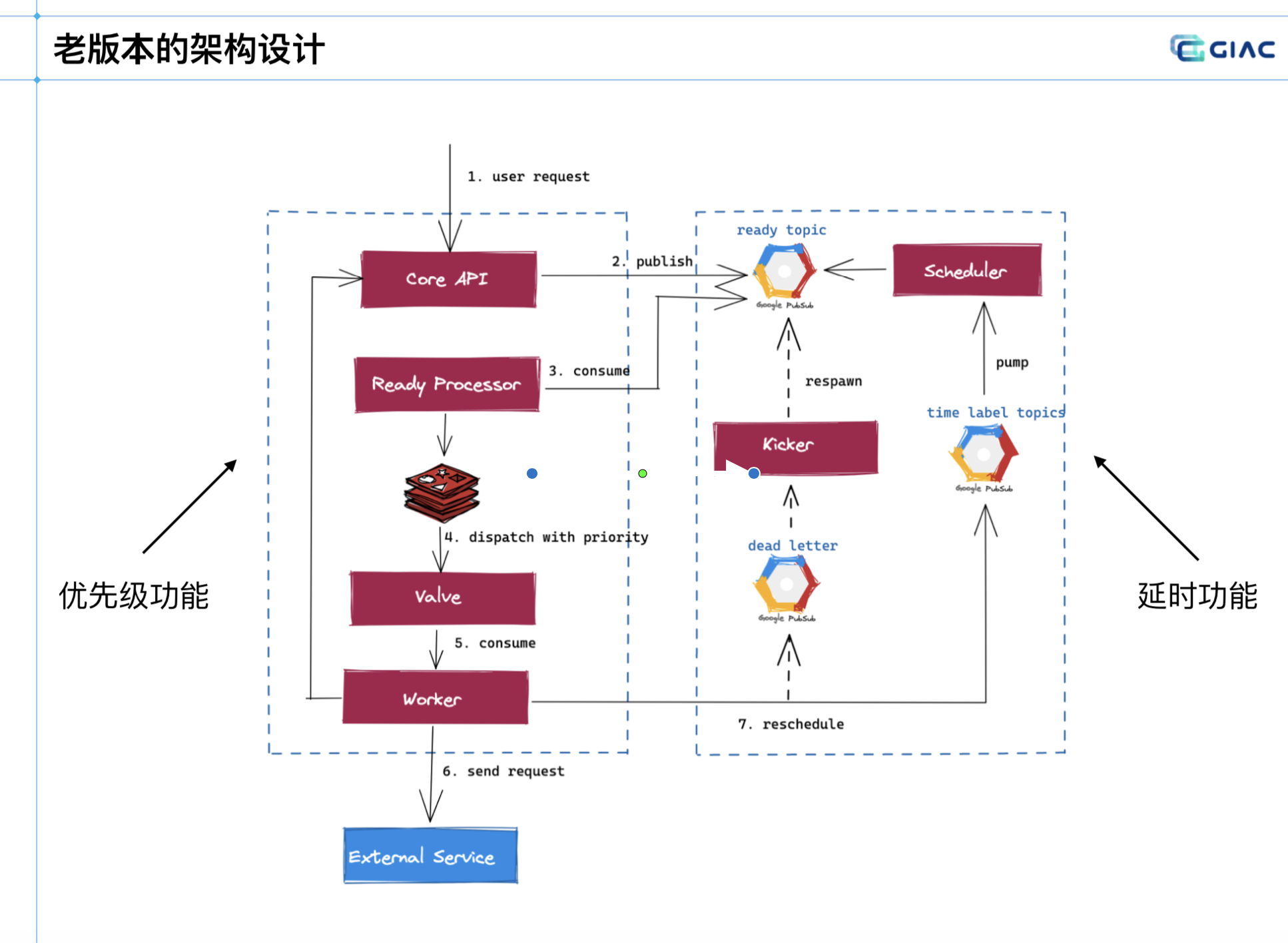
存在以下问题:
- 会导致出现波峰,资源浪费。
- 设计过于复杂,导致系统脆弱。
- 链路过长,定位困难。
- 错误的 FIFO 实现。
新版本
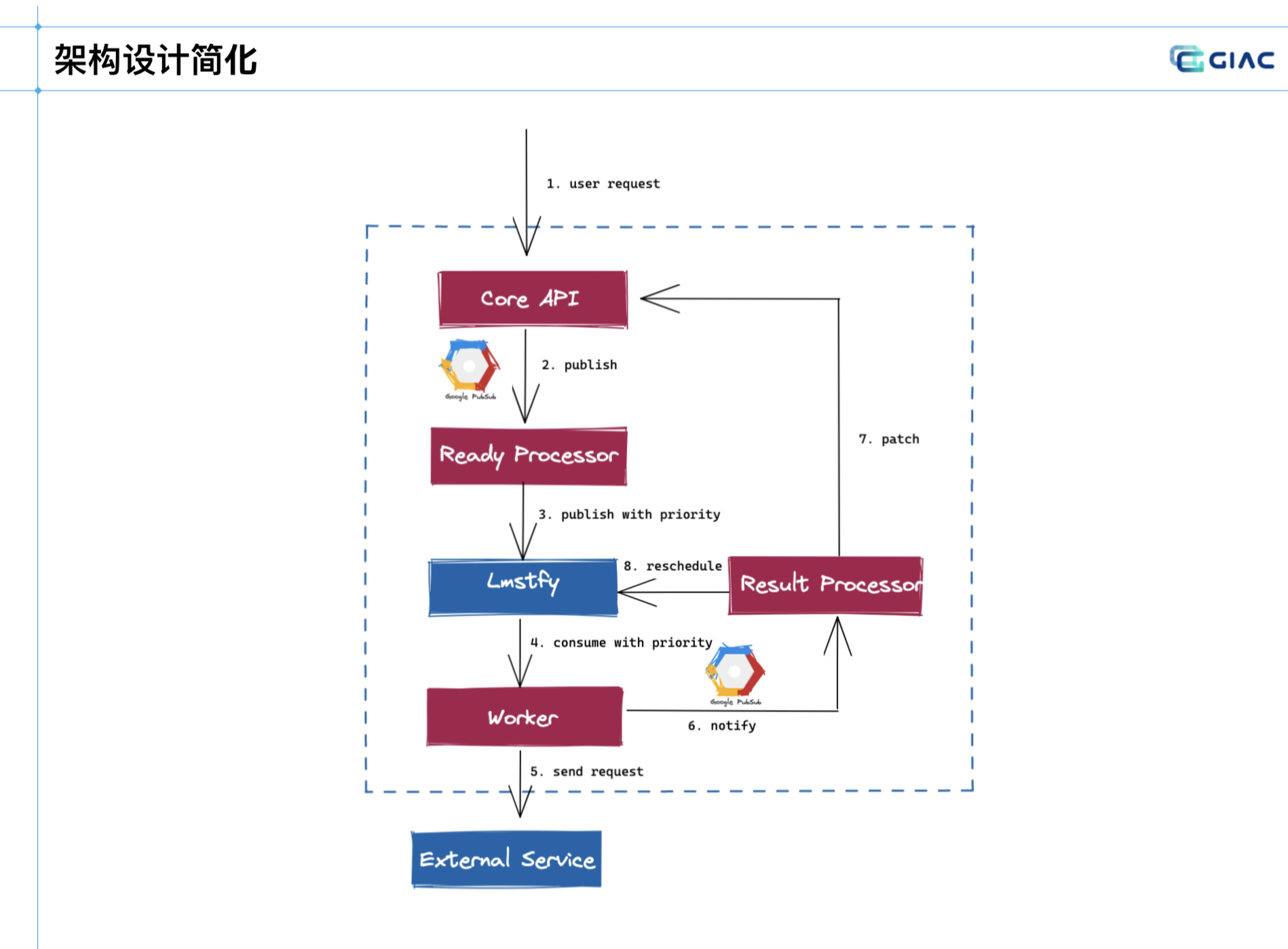
解决思路:
- 通过 LMSTFY 任务队列,解决延迟和优先级功能,解耦业务。
- 基于 Redis,正在做二级存储,冷热数据隔离。
- 通过指定多个队列,来实现多个优先级调度。取多个队列,A队列有内容,则优先消费A。
- 通过实现接口来队列多个数据存储。
- 借助组件的特性和系统优化,简化了架构。
小结
相当于是看了一个任务调度系统的设计发展史,理论上设计的存储和方案不一定得选 Redis 或是 LMSTFY。
不过考虑到演讲者的背景,因此趋向了这个技术方案,也可以从中看到后续任务调度系统规模更大后,可能出现的问题。
快手前端实时性能监控和稳定性度量
公司内也有类似的系统,与快手的前端 APM 是一模一样的定位,可以借此看看成熟的系统的选型和发展情况。
前端的数据
需要有统一性能指标,用一个指标代表:
-
早期:DCL,Onload,来判断前端页面的性能。页面依赖接口数据容易被绕过,长页面不能反映用户真实感知。
-
设想指标的作用:希望获取白屏时间,代表白屏到非白屏的时间。
但发现也无法保证,计算白屏可能会导致客户端崩溃。不能代表页面核心内容的时间:
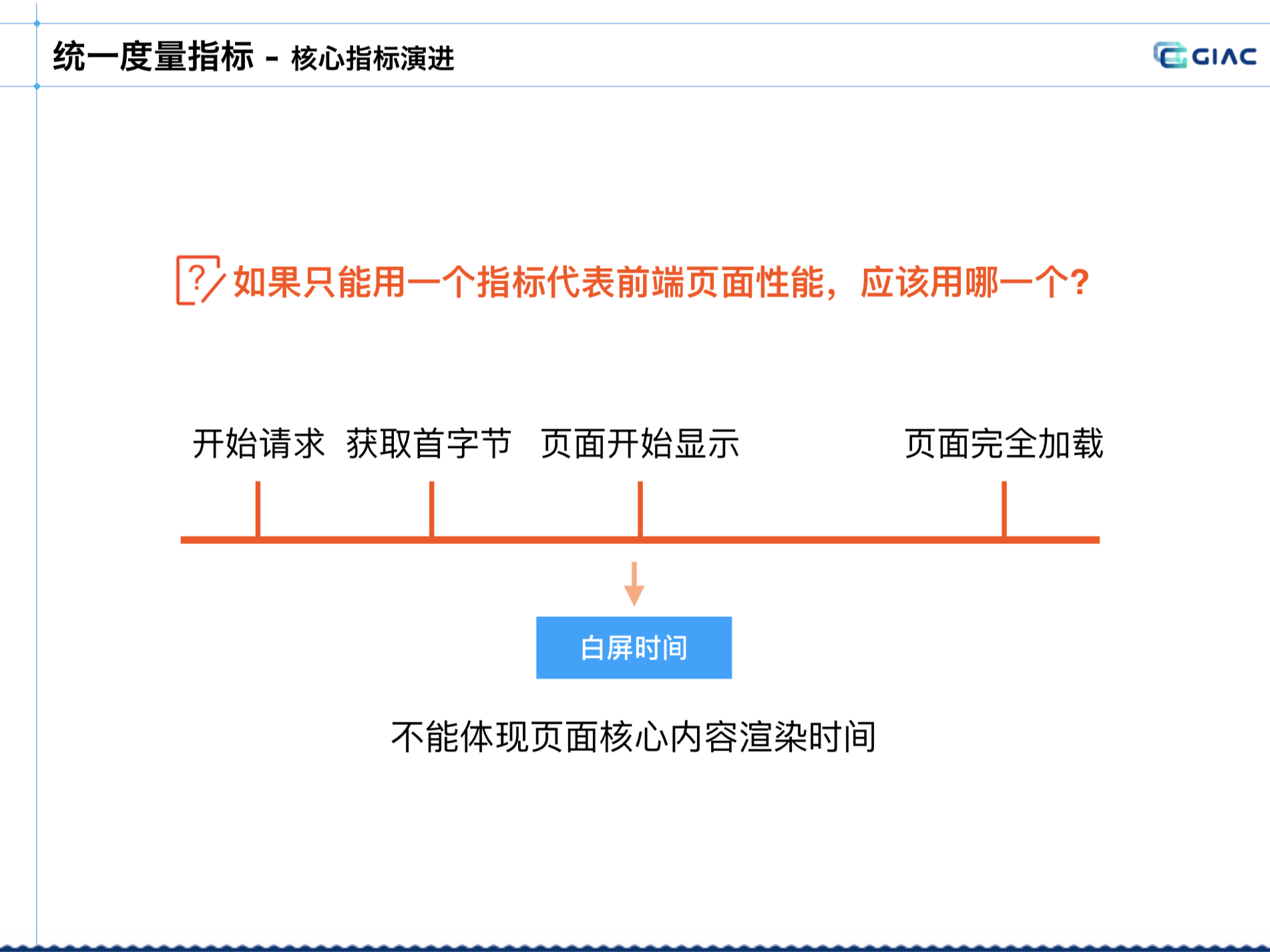
转为目的是拿到主要内容渲染的时间,业内常见用 FMP、LCP:
- FMP(First Meaningful Paint):没有标准实现,对页面细微变化或于敏感。某一个 DOM 内部有很多个节点,可能会造成误差。
- LCP(Largest Contentful Paint):页面内最大内容的渲染时间,最大元素不一定是最重要的元素,例如新闻内的图片。并且浏览器的支持率只有 70%(致命),因为快手很多低端机是不支持的。
真正要的指标
考虑业务需要的指标是什么,本质上业务的真正内容是从接口异步获取回来的。
因此采取了自定义 FMP,API 响应数据渲染到页面后的时间,代表页面的性能:

这个自定义方案要业务自己计算的,会调用提供的统一方法来计算。虽然有一定侵入,但准确性最高,最有效。
主要有以下三种统一度量指标:
- API 性能/异常。
- 资源性能/异常。
- 脚本异常。
也做了容器的性能数据,例如:webview 的启动时间比较慢。提前缓存,可以大幅度提升性能。
小结
大篇幅主要是介绍了前端指标的定义和摸索过程,这是一个平台的基石数据了。
后续的平台能力拓展如下:
- 在排查问题上:他们做了根因定位,分析了许多前端的具体指标,基本达到出现异常 5 分钟内可通知到业务,10 分钟内给出解决方案建议。
- 在大数据量上:动态采样,批量上报,数据上报保障,异常场景兜底(例如:异常上报不上来,会在恢复后上报异常退出了页面,会记录堆栈信息)
- 在性能拓展上,做了性能周报,主动给业务推,便于他们实时的跟踪自己的情况。也做了数据大屏做全局视角的分析。
快手中间件 mesh 化实践
分享是介绍中间件相关的 mesh,比较有意思的是定义了目前业内 mesh 的三代阶段,这倒是没怎么听过。
具体的定义如下:
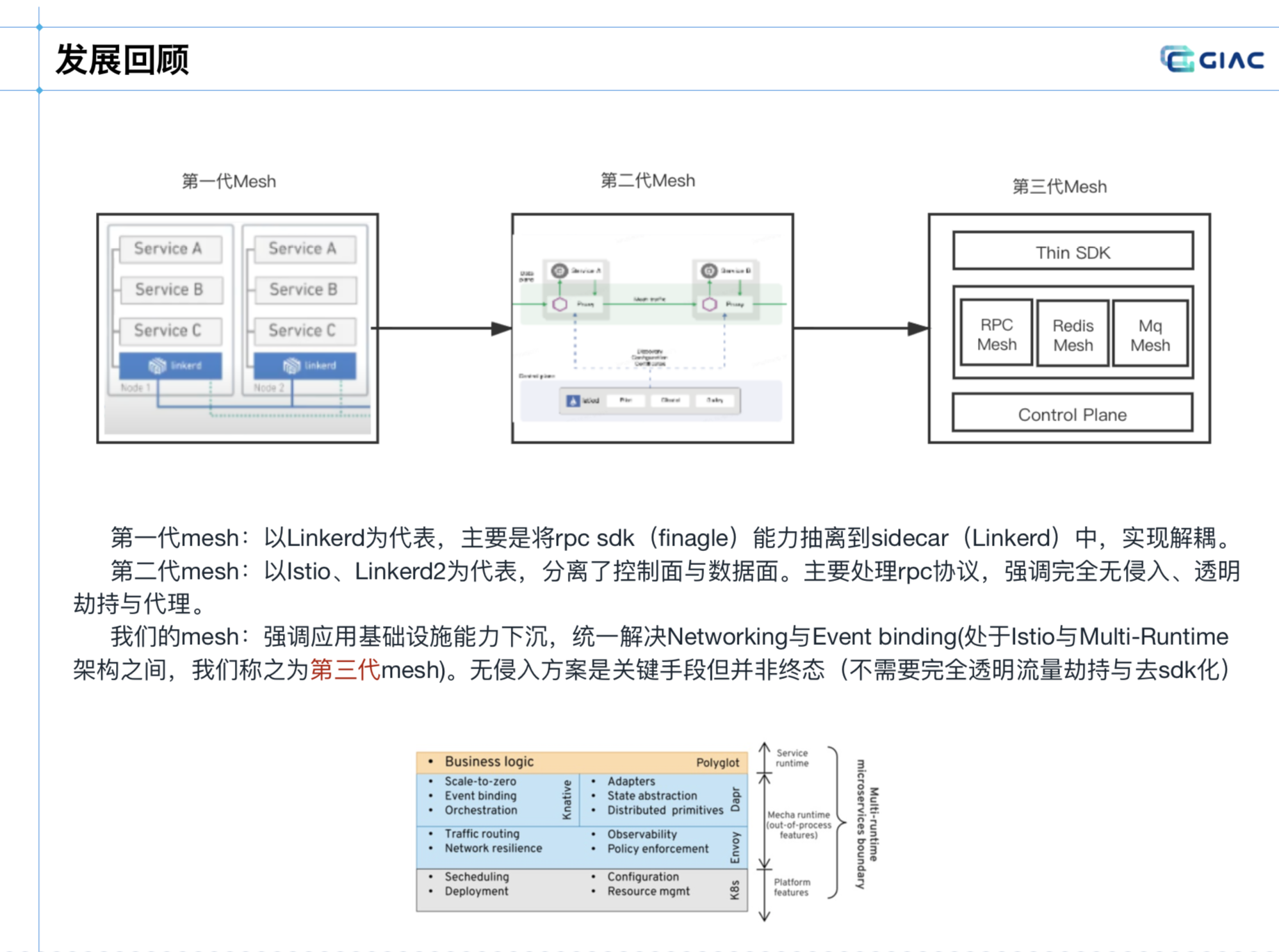
快手中间件采取的是:第三代中间件 mesh,轻 sdk 的方式。
选型考虑
在以往,重 sdk 下,整体开发维护成本,升级都比较繁琐,代理业务协议的流量。
如果是以 Istio、Linkerd2 为代表,主要是处理常见的通讯协议(例如:HTTP、gRPC 协议),又对中间件 mesh 不大合适。
最终采取的是 mesh 加轻 SDK 的方式:
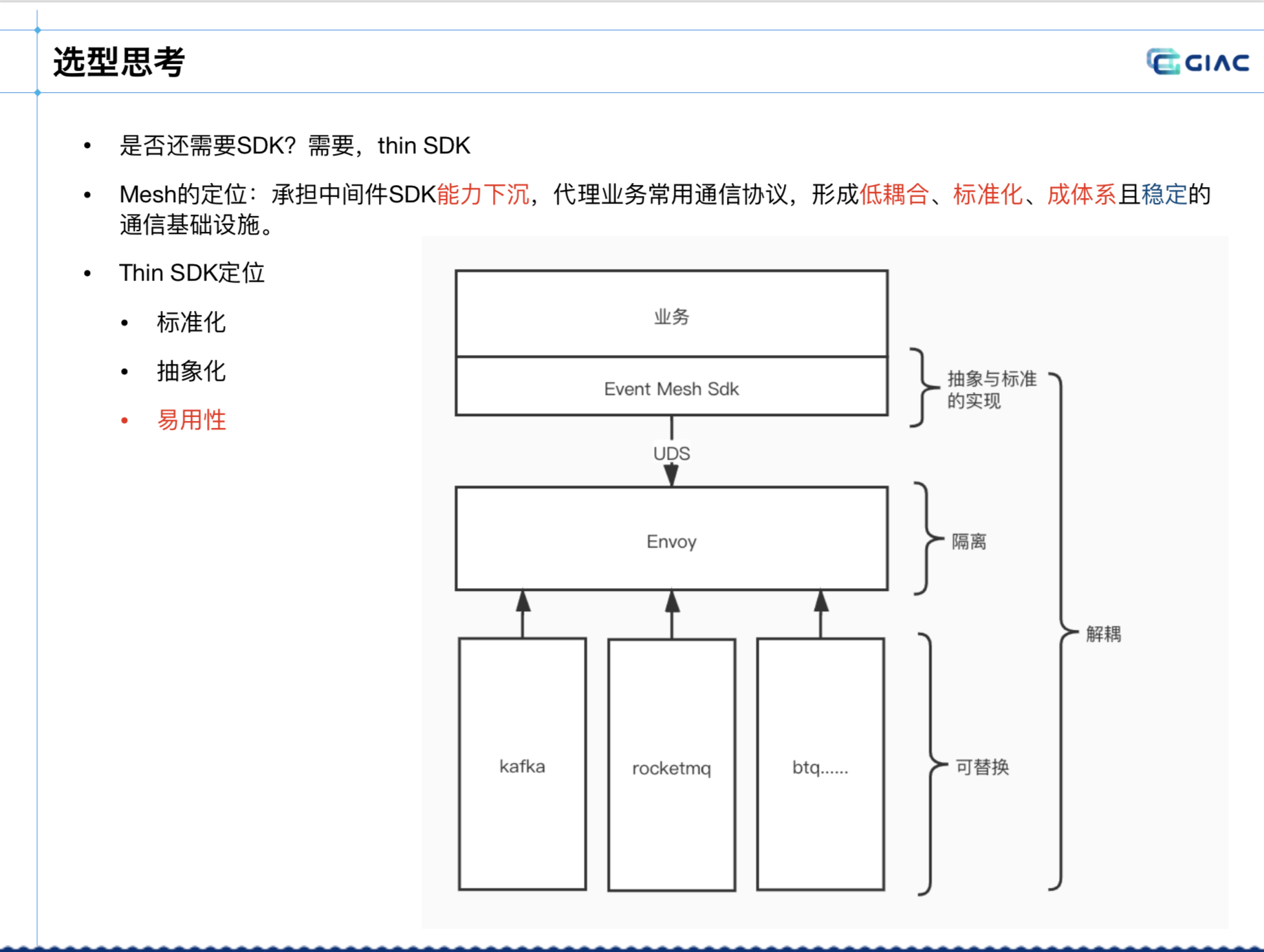
在此 mesh 的定位是能力下沉,sdk 的定位是标准化的定义。
新的挑战
做过微服务,基础设施的小伙伴都知道,要达到 A,将会在 BCD 付出更多,这是常态。
要上 mesh 非常简单,K8s 里几条命令的事。但后面要处理的事,可就是要切切实实的成本了。
主要面临了如下挑战:
- 成本问题:复杂环境下的统一部署与运维。
- 复杂度问题:规模大、性能要求高、策略复杂。
- 落地推广:对业务来说不是强需求。
解决方案
针对以上三点,又配套了做了如下解决方案和措施:
-
统一运维:对自己,网关的运维平台。对业务,定位排查,可观察性的。
-
规模大问题:对 Enovy 等做了二开。只传输变更的数据、按需获取,解决单实例服务数过多的问题。
-
性能要求高:协议栈的优化、序列化优化等,做了大量底层的优化。
-
实施了面向失败设计,SDK fallback,可以 fallback 切换为直连模式。如果是新功能,没有老的,会切换到 Proxy 模式。
业务推广
业务推广这点要单独拧出来讲,因为 mesh 一般的直接收益不是业务,是基础设施,对业务不是强需求会遇到:
- 业务对性能,稳定性敏感。
- 业务很难配合人力配合架构升级。
- 对业务侧的收益并不明显。
据闻现在业内大规模落地的只有字节和蚂蚁,且都是有很多背景因素的,和组织上的人有直接关系。
关于业务推广,演讲者也给出了一些建议,例如:稳定性很重要,搭便车,业务共建,选型有明显业务收益等。
小结
近几年各家都纷纷出来分享 mesh,其实基本上现状和应用情况都比较清晰了。
像本次快手 mesh 的分享主要是面向中间件(gRPC、Kafka、RocketMQ、ZK、Mongo、Redis、MySQL)等。
但能明显感觉到业务推广的苦恼,以及可预测的运维投入巨大,这也是所有出来分享 mesh 的核心痛点分享。
其余的技术细节,大多通过二开等方案解决了。
