想要4个9?本文告诉你监控告警如何做
“你说说,没有仪表盘的车,你敢开吗?”
“没有仪表盘的车开在路上,你怎么知道现在是什么情况?”

“客户说你这车又崩了,咋知道什么时候好的?啥时候出的问题?”
前言
将思考转换到现实的软件系统中,可想而知没有监控系统的情况下,也就是没有 ”仪表盘“ 的情况下实在是太可怕了。
你的故障永远都是你的客户告诉你的,而…在什么时候发生的,你也无法确定,只能通过客户的反馈倒推时间节点,最后从错误日志中得到相对完整的日志信息。
问题
更要命的是你无法掌握主动权,错误日志有可能会有人漏记录,平均修复时间(MTTR)更不用想了,需要从 0.1 开始定位,先看 APP 是哪个模块报错,再猜测是哪个服务导致,再打开链路追踪系统,或是日志平台等。
稍微复杂些的,排查来来往往基本都是半小时、一小时以上,那 4 个 9 肯定是达不到的了,以此几次 P0 几小时怕不是业务绩效也凉凉,因为故障修复的速度实在是太慢了。
那归根到底,想破局怎么办,核心第一步就是要把监控告警的整个生态圈给建设好。
监控定义
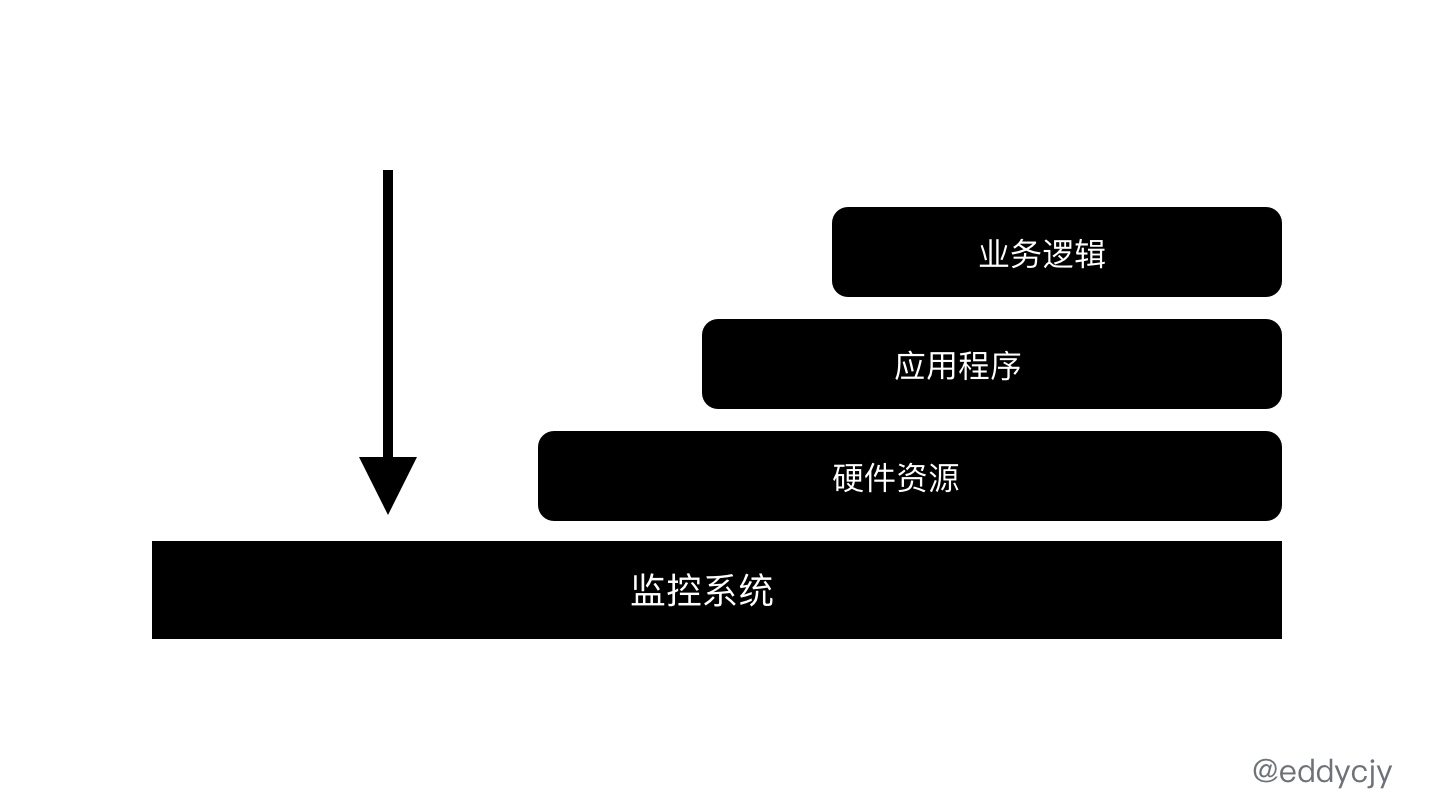
常说监控监控,监控的定义就是监测和控制,检测某些事物的变化,以便于进行控制。在常见的软件系统中,大多分为三大观察类别:
-
业务逻辑:项目所对应的服务其承担的业务逻辑,通常需要对其进行度量。例如:每秒的下单数等。
-
应用程序:应用程序。例如:统一的基础框架。
-
硬件资源:服务器资源情况等。例如:Kubernetes 中的 Cadvisor 组件便会提供大量的资源指标。
从软件系统来讲,监控的定义就是收集、处理、汇总,显示关于某个系统的实时量化数据,例如:请求的数量和类型,错误的数量和类型,以及各类调用/处理的耗时,应用服务的存活时间等。
监控目标
知道了监控的定义,了解了监控的作用和具体的实施指标后。我们需要明确的知道,做监控的目标是什么:
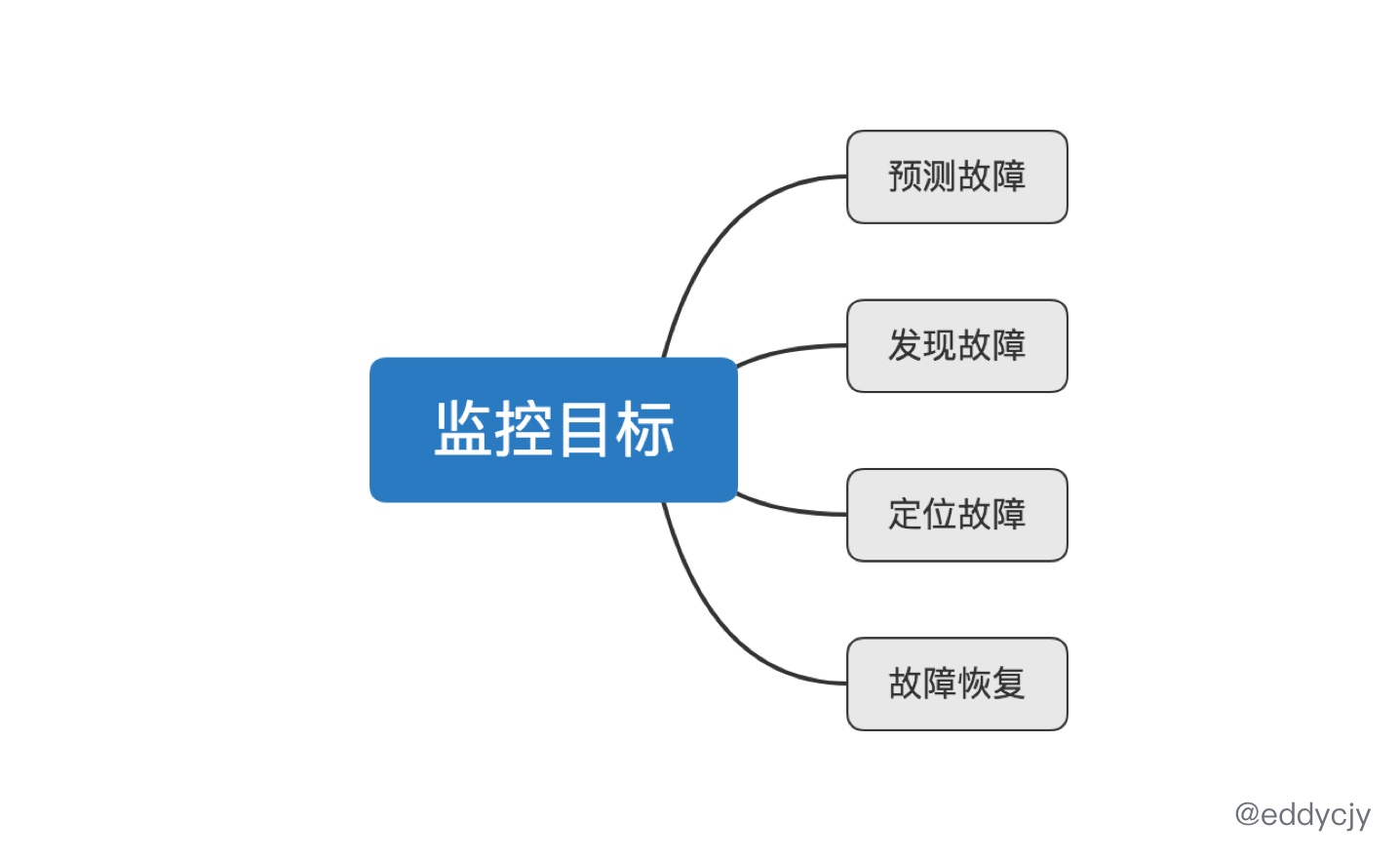
从现实层面出发,做监控的初衷,就是希望能够及时的发现线上环境的各种各样奇奇怪怪的问题,为业务的正常运转保驾护航。因此整体分为上图四项:
-
预测故障:故障还没出现,但存在异常。监控系统根据流量模型、数据分析、度量趋势来推算应用程序的异常趋势,推算可能出现故障的问题点。
-
发现故障:故障已经出现,客户还没反馈到一线人员。监控系统根据真实的度量趋势来计算既有的告警规则,发现已经出现故障的问题点。
-
定位故障:故障已经出现,需要监控系统协助快速定位问题,也就是根因定位(root cause)。此时是需要协调公司内生态圈的多个组件的,例如:链路追踪系统、日志平台、监控系统、治理平台(限流熔断等),根据监控系统所告警出来的问题作为起始锚点,对其进行有特定方向的分析,再形成 ”线索“ 报告,就可以大力的协助开发人员快速的定位问题,发现故障点。
-
故障恢复:故障已经出现,但自动恢复了,又或是通过自动化自愈了。这种情况大多出现在告警规则的阈值配置的不够妥当,又或是第三方依赖恰好恢复了的场景。
而更值得探讨的的是监控告警的后半段闭环,故障自愈,通过上述三点 “预测故障、发现故障、定位故障”,已经定位到故障了,就可以配合内部组件,实现自动化的 ”自愈“,减少人工介入,提高 MTTR。

因此做监控系统的目标很明确,就是发现问题,解决问题,最好自愈,达到愉快休假,业务安心的目的。
4 个黄金指标
有定义,有目标,那指导呢。实际上 “业务逻辑、应用程序、硬件资源” 已经成为了一个监控系统所要监控构建的首要目标,绝大部分的监控场景都可以归类进来。且针对这三大项,《Google SRE 运维解密》 也总结出了 4 个黄金指标,在业界广为流传和借鉴:
-
延迟:服务处理某个请求所需要的时间。
- 区分成功和失败请求很重要,例如:某个由于数据库连接丢失或者其他后端问题造成的 HTTP 500 错误可能延迟很低。因此在计算整体延迟时,如果将 500 回复的延迟也计算在内,可能会产生误导性的结果。
- “慢” 错误要比 “快” 错误更糟糕。
-
流量:使用系统中的某个高层次的指标针对系统负载需求所进行的度量。
- 对 Web 服务器来讲,该指标通常是每秒 HTTP 请求数量,同时可能按请求类型分类(静态请求与动态请求)。
- 针对音频流媒体系统来说,指标可能是网络 I/O 速率,或者并发会话数量。
- 针对键值对存储系统来说,指标可能是每秒交易数量,或每秒的读者操作数量。
-
错误:请求失败的速率。
- 显式失败(例如:HTTP 500)。
- 隐式失败(例如:HTTP 200 回复中包含了错误内容)。
- 策略原因导致的失败(例如:如果要求回复在 1s 内发出,任何超过 1s 的请求就都是失败请求)。
-
饱和度:服务容量有多 “满”,通常是系统中目前最为受限的某种资源的某个具体指标的度量,例如:在内存受限的系统中,即为内存;在 I/O 受限的系统中,即为 I/O。
- 很多系统在达到 100% 利用率之前性能会严重下降,因此可以考虑增加一个利用率目标。
- 延迟增加是饱和度的前导现象,99% 的请求延迟(在某一个小的时间范围内,例如一分钟)可以作为一个饱和度早期预警的指标。
- 饱和度需要进行预测,例如 “看起来数据库会在 4 小时内填满硬盘”。
如果已经成功度量了这四个黄金指标,且在某个指标出现故障时能够发出告警(或者快要发生故障),那么在服务的监控层面来讲,基本也就满足了初步的监控诉求。
也就是可以做到知道了是什么出问题,问题出在哪里,单这一步就已经提高了不少定位问题的时间效率,是一个从 0 到 1 的起步阶段。
实践案例
知道是什么(定义),为什么要做(目标),做的时候需要什么(4 个黄金指标)后,还缺乏的是一个承载这些基础应用、业务思考的平台,让架构+运维+业务共同在上面施展拳脚。
公司内部至少需要有一个监控告警管理平台。
平台搭建
在目前云原生火热的情况下,Kubernetes 生态中大多惯用 Prometheus,因此 Prometheus+Grafana+AlertManger 成为了一大首选,业内占比也越来越高,其基本架构如下:
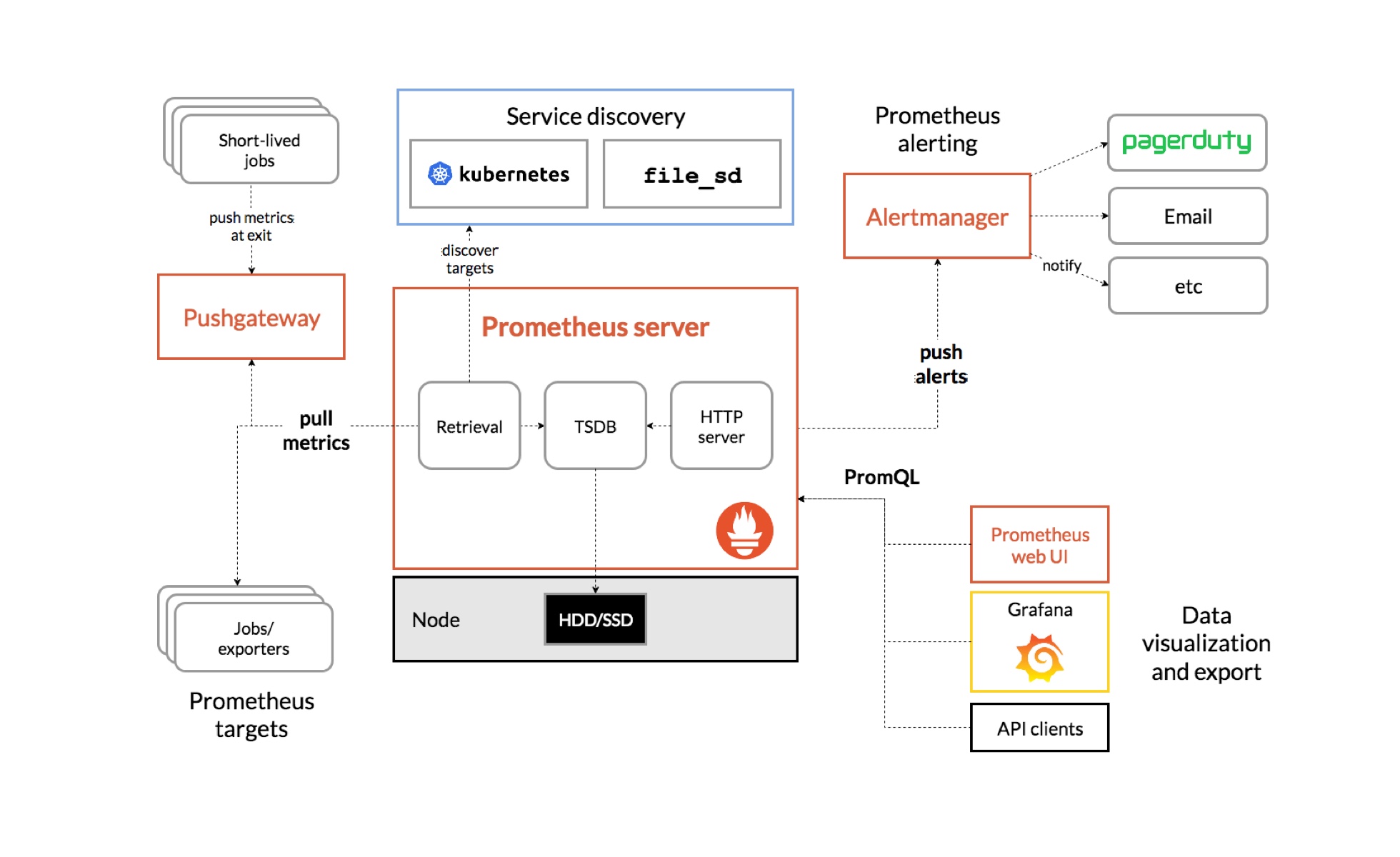
- Prometheus Server:用于收集指标和存储时间序列数据,并提供一系列的查询和设置接口。
- Grafana:用于展示各类趋势图,通过 PromQL 从 Prometheus 服务端查询并构建图表。
- Alertmanager:用于处理告警事件,从 Prometheus 服务端接收到 alerts 后,会进行去重,分组,然后路由到对应的Receiver,发出报警。
这块具体的基本知识学习和搭建可详见我写的 Prometheus 系列,本文不再赘述。
监控指标
在平台搭建完毕后,常要做的第一步,那就是规划你整个系统的度量指标,结合 Google SRE 的 4 个黄金指标,可以初步划分出如下几种常用类型:
-
系统层面:Kubernetes Node、Container 等指标,这块大多 Cadvisor 已采集上报,也可以安装 kube-state-metrics 加强,这样子就能够对 Kubernetes 和应用程序的运行情况有一个较好的观察和告警。
-
系统层面:针对全链路上的所有基础组件(例如:MySQL、Redis 等)安装 exporter,进行采集,对相关基础组件进行监控和告警。
-
业务服务:RPC 方法等的 QPS 记录。可以保证对业务服务的流量情况把控,且后续可以做预测/预警的一系列动作,面对突发性流量的自动化扩缩容有一定的参考意义。
-
业务服务:RPC 方法等的错误情况。能够发现应用程序、业务的常见异常情况,但需要在状态/错误码规划合理的情况下,能够起到较大的作用,有一定困难,要在一开始就做对,否则后面很难扭转。
-
应用程序:各类远程调用(例如:RPC、SQL、HTTP、Redis)的调用开销记录。最万金油的度量指标之一,能够在很多方面提供精确的定位和分析,Web 应用程序标配。常见于使用 P99/95/90。
-
语言级别:内部分析记录,例如:Goroutines 数量、Panic 情况等,常常能发现一些意想不到的泄露情况和空指针调用。没有这类监控的话,很有可能一直都不会被发现。
指标落地
第一步完成了整个系统的度量指标规划后,第二步就是需要确确实实的把指标落地了。
无论是统一基础框架的打点,系统组件的 exporter,大多涉及了公司级的跨多部门协作,这时候需要更多的耐心和长期主义和不断地对方向纠错,才能尝到体系建设后的果实。
告警体系
在完成监控指标和体系的建设后,告警如何做,成为了一大难题,再好的监控体系,闭环做不好,就无法发挥出很大的作用。因此我们给告警定义一些准则:
-
告警不要太多,否则会导致“狼来了”。
-
告警出现时,应当要具体操作某些事情,是亟待解决的。
-
告警出现时,应当要进行某些智力分析,不应该是机械行为。
-
不需要人工响应/处理的告警规则,应当直接删除。
-
告警出现时,你下意识要再观察观察的告警,要直接进行调整。
-
告警应当足够的简单,直观,不需要猜。
简单来讲就是告警要少,事件需要解决,处理要人工介入。否则右拐自动化自愈恢复可能更香。
告警给谁?
另外一个难题就是: 谁诱发处理的告警,要通知给谁?
这是一个很需要斟酌的问题,在告警的规范上,尽可能遵循最小原则,再逐级上报。也就是先告警给 on-call 人,若超出 X 分钟,再逐级上报到全业务组,再及其负责人,一级级跟踪,实现渐进式告警。
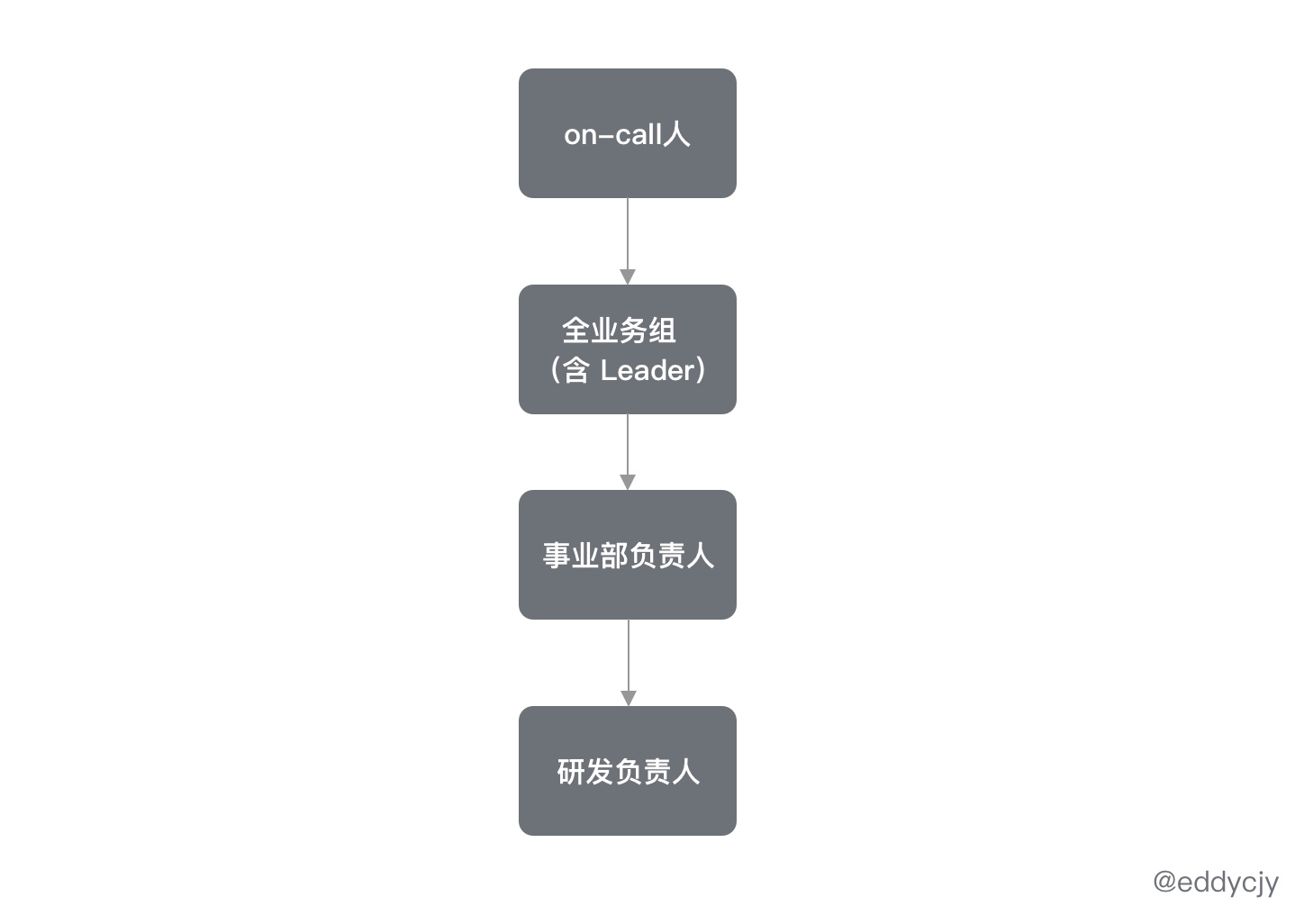
逐级上报,响应即跟踪,明确问题点的责任人。而逐级上报的数据来源,可通过员工管理系统来获取,在员工管理系统中有完整的上下级关系(类似 OA 审批上看到的流程节点),但如果该系统没有开放 API 之类的,那可能你只能通过其他方式来获取了。
例如像是通过企业微信获取部门关系和人员列表,再手动设置上下级关联关系,也可以达到目的,且在现实世界中,有可能存在定制化的诉求。
规范建立
即使所以监控体系、指标落地、告警体系都建立起来了,也不能掉以轻心。实际上在成为事实标准后,你仍然需要尽快为告警后奔跑,将整个闭环搭建起来,也就是故障管理。
与公司内部的流程管理的同学或 QA,一起设立研发底线的规范,进行细致的告警分级识别,告警后的汇总运营分析,形成一个真正意义上的故障管理规范。
否则最后可能会疲于奔命,人的时间精力总是有限的,而面对整个公司的监控告警的搭建,体系上与业务组的共建,督促告警响应,极有可能最后会疲于奔命,即使真的有一定用处,在杂乱无人收敛的告警中最后流于形式。
总结
监控告警的体系生态做来有意义吗?
这是必然的,成熟且规范的监控告警的体系生态是具有极大意义,可以提前发现问题,定位问题,解决问题。甚至这个问题的说不定还不需要你自己处理,做多组件的闭环后,直接实施自动化的服务自愈就可以了,安心又快快乐乐的过国庆节,是很香的。
而故障管理的闭环实施后,就可以分析业务服务的告警情况,结合 CI/CD 系统等基础平台,每季度自动化分析实施运营报表,帮助业务发现更多的问题,提供其特有的价值。
但,想真正做到上述所说的成熟且规范,业务共建,有难度,需要多方面认同和公司规范支撑才能最佳实现。因此共同认可,求同存异,多做用户反馈分析也非常重要。
